Fast Matrix Products and Other Amazing Results
Some amazing mathematical results

Volker Strassen has won many prizes for his terrific work in computational complexity—including the Cantor medal, the Paris Kanellakis Award, and most recently the Knuth Prize. He is perhaps most famous for this brilliant work on matrix multiplication, but he has done so many important things—others may have their own favorites.
Today I plan on talking about some amazing results. Two are classic results due to Strassen, and the third is a recent result related to boolean matrix products.
I will have to do another longer discussion on “Amazing Mathematical Results.” I need to think, first, how I would define them—for today I will just give three examples.
Fast Matrix Product
Strassen’s 1969 result Gaussian Elimination is not Optimal shows, of course, a way to multiply two 
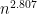
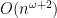

The current best matrix product algorithm is now due to Don Coppersmith and Shmuel Winograd, and runs in time 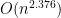
There is a story—I believe is true—how Strassen found his terrific algorithm. He was trying to prove that the naive cubic algorithm is optimal. A natural idea was to try and prove first the case of two by two matrices—one by one matrices are trivial. One day he suddenly realized, if there was a way to multiply two by two matrices with 
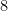

All For The Price of One
Strassen also has another amazing result, in my opinion, on arithmetic circuits—this is joint work with Walter Baur. They have used this result to get some tight lower bounds on arithmetic computations. In 1983 they proved their result about the arithmetic straight-line complexity of polynomials: let 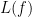

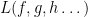
denote the minimum number of operations needed to compute the polynomials 



Theorem: For any polynomial
,
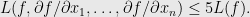
Thus, the cost of computing
This result has been used to get lower bounds: this was why Baur and Strassen proved their result. The general method is this:
- Argue the cost of computing
is
.
- Then, reduce computing these
- This implies by Baur-Strassen’s theorem, the cost of
must be at least
The critical point is proving a lower bound on the cost of one polynomial may be hard, but proving a lower bound on the cost of
Finding Triangles
Virginia Vassilevska Williams and Ryan Williams have proved a number of surprising results about various matrix products and triangle detection.
One of the long standing open questions is what is the complexity of determining if a graph has a triangle? That is does the graph have three distinct vertices 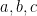

One way to detect this is to use matrix product—invoke Strassen, now Coppersmith-Winograd. Another approach is combinatorial. It is easy to see that there is an algorithm that runs in time order

Of course, this can be as large as cubic in the number of vertices.
What Williams and Williams consider is the following question: is there a relationship between detecting triangles and computing boolean matrix products? They also consider the same type of question between boolean matrix verification and boolean matrix products.
The surprise is that the ability to detect triangles or the ability to verify boolean products, can also be used to compute boolean matrix products. What is so surprising about this is these both return a single bit, while matrix product computes many bits. How can a single bit help compute many bits? The simple answer is that it cannot—not without some additional insight. Their insight is that the algorithms can be used over and over, and in this manner be used to speedup the naive boolean matrix product.
One Bit, Two Bits, Three Bits,
Let me give a bit more details on what they prove, not on how they prove it. See their paper for the full details. Since they prove many theorems, I will state just one.
Theorem: Suppose Boolean matrix product verification can be done in
time for some
. Then graph triangle detection on
-node graphs can be done in
Note, matrix product verification is simple with randomness, but boolean matrix product seems much harder to check. Recall, to check that 

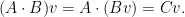
This can be done in 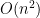
Open Problems
The main open problems are of course to finally resolve the exponent on matrix product—is it possible to multiply in 
[3–>5 in the Derivative Lemma statement—see Morgenstern’s linked paper for why]
Trackbacks
- Zest for Graphics :: Acerca de la multiplicicación rápida de matrices :: April :: 2010
- Projections Can Be Tricky « Gödel’s Lost Letter and P=NP
- Cricket, 400, and Complexity Theory « Gödel’s Lost Letter and P=NP
- Mathematical Mischief Night « Gödel’s Lost Letter and P=NP
- Thanks For Sharing « Gödel’s Lost Letter and P=NP
- The More Variables, the Better? | Gödel's Lost Letter and P=NP
- Open Problems That Might Be Easy | Gödel's Lost Letter and P=NP
- Transposing | Gödel's Lost Letter and P=NP
- The Shortest Path To The Abel Prize | Gödel's Lost Letter and P=NP
- The Shortest Path To The Abel Prize - 2NYZ
- Baby Steps - 51posts
- Baby Steps | Gödel's Lost Letter and P=NP


Any version of “How to compute fast a function and all its derivatives: a variation on the theorem of Baur-strassen” not trapped behind a pay-wall?
Here is a survey with a proof sketch of a version of Baur Strassen.
Jacques Morgenstern in “How to compute fast a function and all its derivatives: a variation on the theorem of Baur-strassen” says:
“From the proof of the theorem we can deduce a constructive, recursive but backwards way to build an algorithm for the computation of all the partial derivatives of ….”.
Do you by any chance know if there is a paper that really describes such an algorithm?
funny, high-probability triangle-freeness detection only requires _constant_ time…
shouldn’t this give me something like a really fast “high-probability matrix product” algorithm?
s.
The Baur-Strassen theorem highlights some interesting differences between arithmetic and Boolean complexity. One of these is the Chain Rule of calculus. It is applied this way in the proof: In the given circuit there is always some gate
there is always some gate  both of whose arguments are inputs, call it
both of whose arguments are inputs, call it  where possibly
where possibly 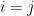 . Let a new variable
. Let a new variable  stand for this gate, and let
stand for this gate, and let  be the resulting circuit of
be the resulting circuit of 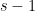 binary gates and
binary gates and  inputs. Then
inputs. Then
Hence by the Chain Rule, for any $k$,
The extra term is zero unless is one of
is one of  or
or  , the only case(s) where
, the only case(s) where  is not already given by the recursive construction applied to
is not already given by the recursive construction applied to  . These one-or-two cases require only a few additional gates to compute the second term in the Chain Rule, which proves the overall linear size of the construction. (The case
. These one-or-two cases require only a few additional gates to compute the second term in the Chain Rule, which proves the overall linear size of the construction. (The case 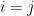 when
when  is a *-gate also introduces a multiplier of 2, the only but important exception to the constants staying bounded.)
is a *-gate also introduces a multiplier of 2, the only but important exception to the constants staying bounded.)
Now the question is, can we imitate this for Boolean functions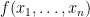 ? The most natural analogue to the derivative seems to me to be the “sensitivity function”
? The most natural analogue to the derivative seems to me to be the “sensitivity function”
which is true at an assignment iff flipping the bit
iff flipping the bit  changes the value of
changes the value of  . Alas, this function not only does not obey an analogous Chain Rule, it does not even satisfy an analogue of the derivative product rule, i.e.\
. Alas, this function not only does not obey an analogous Chain Rule, it does not even satisfy an analogue of the derivative product rule, i.e.\ 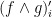 fails to equal
fails to equal 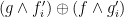 . Trying to find something else that works strikes me as a wonderful way to “waste” a sunny afternoon… 🙂
. Trying to find something else that works strikes me as a wonderful way to “waste” a sunny afternoon… 🙂
Whoops, two glitches (lack of preview for comments(?) and the fact of my simultaneously needing to chase my kids out to enjoy a sunny afternoon), “\partial” was missing the “\”, and the non-parsing formula was just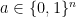 . This may also be enough of a sketch to answer John Mount’s query; I started some hours ago before seeing that comment…
. This may also be enough of a sketch to answer John Mount’s query; I started some hours ago before seeing that comment…
An easier related task is to produce a circuit that takes auxiliary inputs and outputs the linear combination
and outputs the linear combination 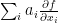 . This gives just 1 output, not n, and I haven’t really found any good applications for it.
. This gives just 1 output, not n, and I haven’t really found any good applications for it.
its good article, share with my at http://www.jogjacartoon.com
In keeping with respect for great truths of all kinds — “One must always invert” (Carl G. J. Jacobi) — “One must not always invert” (Shalosh B. Ekhad) — let’s try to invert the theme of this post … just to see if any interesting questions arise.
In geometry, matrices are associated with linear transforms … among the most interesting transforms are those associated with (co)tangent spaces … and among the most ubiquitous tangent-space transforms are the “musical” isomorphisms with which Riemannian and symplectic manifolds are naturally endowed.
Now, what kind of geometric objects have a musical isomorphism that is described by a large-dimension general matrix? The interesting answer is that this class of geometric objects appear to be very uninteresting … or possibly very unnatural … or at the very least, uncommonly met in practice.
The large-dimension geometric manifolds that arise in practice ubiquitously have some structure that allows raising-and-lowering to be accomplished via matrices that are sparse … banded … factorizable … that are computationally special in some way.
Thus we feel that somehow these theorems about matrix multiplication are telling as also about the computational hardness of describing geometry … and also, that in practice, humans have an aversion to working with geometries that are hard-to-describe.
Just to be clear: by “boolean matrix product” you do not mean taking the product of matrices whose entries are in F_2. (Where verification is easy.) Looking at the Vassilevska-WIlliams-Williams paper, you seem to mean matrix product where the entries are in an arbitrary boolean semiring.
While it’s certainly true that Strassen’s matrix multiplication algorithm scales sub-cubicly, and it’s an interesting result, I would hesitate to call it “fast”.
Even with quite large dense matrices (thousands by thousands), comparing optimized brute force vs. optimized Strassen’s, brute force wins hands down. For larger matrices, the instability of Strassen’s algorithm can mean that its output isn’t valid anyway. It may be different for sparse matrix representations, though.
You are dead on a key issue I have talked about many times. The word “fast” used in theory does not always—ever?—translate into practice.
Great point. But still a great result. Perhaps one day we will have really fast algorithms for matrix products.
I think it does sometimes translate into practice; it’s just a matter of how generally. The famous O(n) median-select algorithm may need trillions of items to surpass “sort, then pick the middle one”, but maybe you have trillions of items… though I suppose in that case, you’d want them split across multiple cores and multiple computers anyway. hmm… Well, a friend mentioned Fibonacci heaps helping with giant fluid dynamics simulations since he had hundreds of millions of items in them. I suppose that counts. 🙂
As for a “fast” matrix product algorithm, it’s no magic bullet, but either brute force or Strassen’s can be parallelized ad nauseum quite easily. Using Strassen’s pattern to parallelize then brute force on each processor might give better computation time than brute force alone if it’s on a single computer. I’d have to test it out to see, though.
Thanks to Dick for the advertisement! Just a few comments.
(1) steve: I’m not sure exactly what you mean, but maybe you are talking about finding algorithms for randomly chosen instances? For random 0-1 matrices, it is known that Boolean matrix product can be done much faster than O(n^3). (I doubt our reduction can be used to prove this, because the triangle detection instances we generate are not totally “random” even if the original matrices are, but I don’t think a reduction is necessary to prove this.)
(2) JK: Yes, by “boolean matrix product” we mean an OR of ANDs, not over GF(2). Our reductions heavily exploit the fact that the summation is an OR instead of a MOD2.
(3) Neil: One of our motivations for studying connections between matrix product and triangle detection is that we hope to uncover alternative methods for matrix products which *are* uncontroversially faster than brute-force in practice, by virtue of being very simple and combinatorial in nature. With Nikhil Bansal, we made some very tiny progress in FOCS last year. (While we did find asymptotically faster combinatorial algorithms for Boolean matrix multiplication, it remains to be seen if they can be made practical!)
(ryan)
oh, i was referring to the graph property testing result. the reliance on triangle having-ness would need not to be super fragile — what can be tested with a constant number of (randomized) queries to the graph adjacency matrix is triangle-freeness, but this constant is actually a function of the “distance from triangle-freeness, if not triangle-free”, where distance is fraction of bitflips required in the adjacency matrix. so differentiating between the two cases: ‘triangle free’, ‘at least epsilon-distance from triangle free’ is constant-query.
as an example, if you needed to differentiate between a constant fraction of triangles and no triangles, i think that you should be able to do this in a constant number of queries to the adjacency matrix.
s.
Neil Dickson remarks … Even with quite large dense matrices (thousands by thousands) …
Hmmm … “quite large” is one of the most relative of all terms … within the world of large-scale dynamical simulation, even a laptop computer will typically work with dense matrices of size 10^6 by 10^6 … and cloud-type simulations work with much larger matrices.
These matrices are so large that they cannot even be stored explicitly, much less manipulated. So there have to be some tricks: the two main tricks are (1) the matrices have factored representations whose storage is compact, and (2) effective preconditioners are available for solving the associated matrix equations iteratively.
Oftentimes, both kinds of tricks are held as trade secrets, because typically they yield an O(n) speedup, where n ~ 10^5 or larger; this amounts to the difference between feasible and infeasible for large classes of problems that are very commonly encountered in the real world.
Partly in consequence of this penchant for trade secrecy, the mathematical literature on these matrix speedup methods is not particularly coherent; now that complexity theorists are taking an interest, perhaps a more unified point-of-view will emerge. That would be great!
While true that “large” is subjective, I dispute that a “laptop computer will typically work with dense matrices of size 10^6 by 10^6”. Using 32-bit floats, that’s 3.6 TB in size for one. You need the space of 3 to do matrix multiplication, which works out to 10.9TB. Storing it factorized to save space means that it’s no longer a dense matrix representation. Additionally, storing on disk means that you’ll want a custom algorithm anyway, not brute force or Strassen’s.
Most definitely you wouldn’t use a single CPU core to do matrix multiplication on it. You’d use a medium-sized cluster or other parallel system. Moreover, as I mentioned, Strassen’s is weakly unstable, so you can’t do a 10^6 by 10^6 matrix multiply using it without taking a big risk that the answer it gives is completely bogus.
Granted, the large-scale simulations I do don’t involve matrix multiplies, but they only take up <100MB of RAM on each machine. That said, if you know how to find the lowest few eigenvalues and eigenvectors of a 2^32 by 2^32 sparse matrix using 2000 unconnected machines (i.e. only using merges and splits) in 1-2 days, please let me know. 😀
We’re talking a little bit a cross-purposes, Neil!
For example, I just now did a 10^6 point complex discrete Fourier transform on my laptop in 0.4 seconds … without having to generate the (dense) transform matrix … which (of course) was achieved by exploiting the factored representation of the fourier transform matrix.
The point of my post was to remind folks that—in practical applications—product representations of matrices are ubiquitous, rather than exceptional. For example, the tensor network state-spaces that the QIT community is embracing, have a factorizable metric; this permits researchers to tackle quantum state-spaces with large-than-classical large numbers of dimensions; and these factorization techniques turn out to be already-known to the protein simulation community.
More broadly, there’s a 2000 article by Charles van Loan, The ubiquitous Kronecker product that discusses … heck, what else to call it? … ubiquity of product representations of matrix transforms.
Indeed, doesn’t Strassen’s original insight amount to recognizing that *all* matrices have computationally efficient product representations? As Van Loan’s article says: “this important matrix operation will have an increasingly
greater role to play in the future.”
Actually much more important problem with Strassen for real-valued matrices beyond it’s practicall slownes (seems to be fast only beyond n=1000 to outperform tuned BLAS), is it’s numerical instability. So if you have LARGE INTEGER valued matrices then why not. But for scientific computation Strassen andVinograd is even more than advised to not use it.
O is O. It is asymptotic complexity not speed. Completely different things, and probably all researchers all knows is it good.
Similar problem is that O notation hides things like costs of arithmetic to be constant, which is not nacassarly true, and can add some additional O(log n), or in patological situations O(n^2) becuase involved integers grows so fast or used real numbers needs to be so accurate to still return correct results.
Great point about stability. Perhaps one could prove that a stable product algorithm must be harder?
Theorem: For any polynomial f(x_1,…,x_n) the cost (in arithmetic operations) of computing f along with the gradient of f is at most three times the cost of computing f.
Isn’t this result a trivial special case of Speelpenning’s thesis (1979), with a constant factor of three instead of six because there is no division in the straight line program, only multiplication and addition?
I was not aware of this result. I apologize for missing it. I will check out the thesis—thanks for informing us of this.