IBM Conference on the Informational Lens
Some differences from the Computational Lens

Chai Wah Wu, Jonathan Lenchner, Charles Bennett, and Yuhai Tu are the moderators for the four days of the First IBM Research Workshop on the Informational Lens. The virtual workshop begins Tuesday morning at 10:45 ET. The conference has free registration and of course is online.
Today we preview the conference and discuss a few of the talks.
The workshop’s name echoes the moniker “Through the Computational Lens” of initiatives led by the Simons Institute at Berkeley and used for a 2014 workshop organized by Avi Wigderson at IAS. A prospectus by the theory group at U.C. Berkeley led off with quantum computing. So will Tuesday’s talks, a full day on quantum by seven leaders we say more about below.
Then the meeting will branch in some different directions from the computational-lens themes. The preface on the workshop website says:
Viewing the world through an informational lens, and understanding constraints and tradeoffs such as energy and parallelism versus reliability and speed, will have profound consequences throughout technology and science. This includes not only mathematics and the natural sciences like physics and biology, but also social sciences such as psychology and linguistics. We aim to bring together leading researchers in science and technology from across the globe to discuss ideas and future research directions through the informational lens.
The other three days have talks that reach into all these areas, a dazzling array. We have made a collage of the twenty-six speakers currently listed on the schedule. Several faces are long familiar but others are novel to us.

Quantum Tuesday
The opening morning has Alexander Holevo between Aram Harrow and Gil Kalai. Among many other accomplishments, Holevo is known for a theorem that implies that 
We don’t have information yet on Aram’s talk. But Gil will update us on the state of his skepticism about the feasibility of large-scale quantum computing. This was the subject of the 2012 debate between Aram and Gil that spanned eight posts on this blog. Here are Gil’s title and abstract:
Computational complexity, mathematical, and statistical aspects of NISQ computers.
Noisy Intermediate-Scale Quantum (NISQ) Computers hold the key for important theoretical and experimental questions regarding quantum computers. In the lecture I will describe some questions about computational complexity, mathematics, and statistics which arose in my study of NISQ systems and are related to:
a) My general argument “against” quantum computers,
b) My analysis (with Yosi Rinot and Tomer Shoham) of the Google 2019 “huge quantum advantage” experiment.
IBM have expressed their own skepticism of Google’s claims, which we mentioned in our own review of the experiment last year. IBM of course also have their own quantum computing initiative.

We may hear about its state from Charlie Bennett, whose talk leads off the afternoon but has yet to be measured, along with the following talk by Isaac Chuang. Then will come Scott Aaronson. If “tomography” in his title sounds to you like a CAT scan, you could consider this a “Schrödinger’s Cat” scan. Well, we should let Scott tell it—the 2018 paper he mentions is this.
Shadow Tomography of Quantum States: Progress and Prospects.
Given an unknown quantum state 

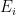
Then Srinivasan Arunachalam, who also works at IBM T.J. Watson in Westchester, NY, will finish the day with another talk about inferring from samples:
Sample-efficient learning of quantum many-body systems.
We study the problem of learning the Hamiltonian of a quantum many-body system given samples from its Gibbs (thermal) state. The classical analog of this problem, known as learning graphical models or Boltzmann machines, is a well-studied question in machine learning and statistics. In this work, we give the first sample-efficient algorithm for the quantum Hamiltonian learning problem. In particular, we prove that polynomially many samples in the number of particles (qudits) are necessary and sufficient for learning the parameters of a spatially local Hamiltonian in 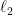
B.Y.O.L.
The workshop has lunch breaks as usual but they are not lunch breaks. Lunch is served at IBM T.J. Watson, and I (Ken) can vouch from times I have been hosted there by Jon Lenchner that the food is wonderful, but attendees will not be on hand to partake. I have known Jon since we were part of the New York area chess scene in the 1970s. Among Jon’s activities in the past five years have been directing IBM’s research center in Nairobi, Kenya, and helping the Toronto Raptors assemble a championship basketball team via player analytics. The latter is not technically related to my chess analytics, but we have greater shared interests in ideas for lower bounds on uniform complexity classes.
Instead of physical lunch, the lunch breaks are moderated panel discussions. So you can bring your own lunch while watching and listening via IBM’s WebEx or other portal. Maybe there will be time for remote attendees to ask questions—though not with your mouth full, as our mothers would say. A few years ago, my department began running catered Friday lunch forums under the name “UpBeat,” but those too are now remote and B.Y.O.L. As for the other thing the “L.” can stand for besides “lunch,” we can mention that the pandemic has rendered onsite restrictions moot.
There will also be Q & A and panel discussion sessions for 45 minutes after each day’s last talk.
Some Other Talks
We wish we could attend all the talks. We imagine they will be available afterward as recordings, but especially when there is live Q & A it is nice to experience them in the moment as at a physically intimate workshop. Rather than list all the speakers and titles here—you can find them on the abstracts page, after all—we will just highlight a few that catch our eye:
Fun facts about polynomials, and applications to coding theory: Mary Wootters.
Here are some (fun?) facts about polynomials you probably already know. First, given any three points, you can find a parabola through them. Second, if you look at any vertical “slice” of a paraboloid, you get a parabola. These facts, while simple, turn out to be extremely useful in applications! For example, these facts are behind the efficacy of classical Reed-Solomon and Reed-Muller codes, fundamental tools for communication and storage. But this talk is not about those facts — it’s about a few related facts that you might not know. Given less than three points’ worth of information, what can you learn about a parabola going through those points? Are there things other than paraboloids that you can “slice” and always get parabolas? In this talk, I will tell you some (fun!) facts that answer these questions, and discuss applications to error correcting codes.
Punch Cards and the Difference Engine: William Gibson and Bruce Sterling.
We discuss the power of the card concept. By storing a finite amount of data on a “punch card” we can structure data handling to be straightforward and safe. The machine we plan will be thousands of times slower than even the first vacuum-tube computers were. But our novel use of steam and punch cards does have merits: cards are physical and help solve security and also privacy issues.
Reasoning about Generalization via Conditional Mutual Information: Lydia Zakynthinou.
We provide a framework for studying the generalization properties of machine learning algorithms, which ties together existing approaches, using the unifying language of information theory. We introduce a new notion based on Conditional Mutual Information (CMI) which quantifies how well the input (i.e., the training data) can be recognized given the output (i.e., the trained model) of the learning algorithm. Bounds on CMI can be obtained from several methods, including VC dimension, compression schemes, and differential privacy, and bounded CMI implies various forms of generalization guarantees. In this talk, I will introduce CMI, show how to obtain bounds on CMI from existing methods and generalization bounds from CMI, and discuss the capabilities of our framework. Joint work with Thomas Steinke.
Rebooting Mathematics: Doron Zeilberger.
Mathematics is what it is today due to the accidental fact that it was developed before the invention of the computer, and, with a few exceptions, continues in the same vein, by inertia. It is time to start all over, remembering that math, is, or at least should be, the math that can be handled by computers, keeping in mind that they are both discrete and finite.
Oh wait, one of these talks is both less novel and more novel than the others. Can a virtual workshop have a virtual virtual talk? The cards were arguably “the” informational lens for almost 100 years.
Open Problems
What have been your experiences with top-of-the-line virtual workshops? Our hats are off to the organizers of this one, and we are looking forward to it.


:star: 😎 <3 music to my ears, good news in a year of darkness+fear, a extremely ambitious undertaking, an early map for 21st century science, the world is finally/ slowly/ inevitably catching up to the visionar(ies). now how about a massive concerted funding push in the age of neoliberal capitalism run amuck, decimating academia and even science itself? an early tribute also here https://vzn1.wordpress.com/2015/06/01/tribute-celebration-of-the-algorithmic-lens/
Update: Aram Harrow’s talk information:
Title: (The quantum information lens on) Optimization and many-body physics
Speaker: Aram Harrow (Massachusetts Institute of Technology)
Abstract: Quantum information theory began by developing quantum analogues of concepts from classical information theory like channel capacity, compression rates, and hypothesis testing. I will talk about how these ideas have found productive application in other areas of computer science, math and physics. One tool in particular – the conditional mutual information – has been useful for understanding applications ranging from classical optimization algorithms to topological order in many-body quantum systems.
Dear Dick & Ken,
It may be worth noting the Information Revolution in our understanding of science began in the mid 1860s when C.S. Peirce laid down what he called the “Laws of Information” in his lectures on the “Logic of Science” at Harvard University and the Lowell Institute. Peirce took up the “the puzzle of the validity of scientific inference” and claimed it was “entirely removed by a consideration of the laws of information.”
Here’s a collection of excerpts and commentary I assembled on the subject —
• Information = Comprehension × Extension
The program page for the workshop has no videotaped recording of about half of the lectures (including mine). It was indeed a lovely workshop, https://sites.google.com/view/informational-lens-workshop-1/schedule?authuser=0