A Strange Horizon
Data science of many things including citations

|
| Amazon India source |
Paul Allison is an emeritus professor of sociology at the University of Pennsylvania and the founder and president of the company Statistical Horizons. They provides short courses and seminars for statistical training.
Today we have a short seminar on statistics and horizons of effectiveness.
Our first topic is about citations. Did we say citations? What are we in research more interested in than citations? Allison co-wrote a paper on a “law” claimed by Alfred Lotka about how the number of citations behaves. Full details in a moment, but two upshots are:
- Over half of the papers are contributed by a few highly prolific authors.
-
One-shot authors are roughly
of the population but account for only a tiny proportion of the literature.
Allison’s Paper
Allison co-wrote his paper, “Lotka’s Law: A Problem in Its Interpretation and Application,” with Derek de Solla Price, Belver Griffith, Michael Moravcsik, and John Stewart in 1976. Lotka’s law, which is related to George Zipf’s famous law, alleges that over any time period in any scientific or literary field, the number 


where 








However, the paper also remarks on a third case, namely making
Horizons
We have mentioned de Solla Price before in regard to his founding scientometrics. In practice this is mainly concerned with citation analysis and other productivity metrics, but its widely-quoted definition, “the science of measuring and analyzing science,” strikes us as broader. We feel there should be a component for measuring limitations of the effectiveness of the science one is practicing.
Now of course in statistics there are longstanding measures of statistical power and experiment acuity and of noise in general. Nevertheless, the cascading “(non-)reproducibility crisis” argues that more needs to be addressed. The development of software tools to counter “p-hacking” exemplifies a new layer of scientific modeling to do so—which could be called introspective modeling.
I will exemplify with two “horizons” that are apparent in my own statistical chess research. One involves estimating the Elo rating of “perfect play.” The other involves the level of skill at which my data may cease to be effective. The former has captured popular imagination—it was among the first questions posed to me by Judit Polgar in a broadcast during the 2016 world championship match—but the latter is my concern in practice. We will see that these may be the same horizon, approached either by looking down from the stars or up from the road.
I am not the first to do this kind of work or face the issue of its resolving power. Matej Guid, Artiz Perez, and Ivan Bratko made it the sole topic of a 2008 followup paper to their 2006 study of all games in world championship matches. But their indicators strike me as weak. Most simply, they do not try to estimate where their horizon is, just argue that their results are not wholly beyond it. We will try to do more—but speculatively. The first step is rock-solid—it is a big surprise I found last month.
More Data, More Resolution
I use strong chess programs to take two main kinds of data. My full model uses programs in an analysis mode that evaluates all available moves to the same degree of thoroughness and takes roughly 4–6 hours per game. My quicker “screening” tests use programs in their normal playing mode, which gives full shrift only to what’s considered the best move, but shaves the time down to 10–15 minutes. For my AAAI 2011 paper with Guy Haworth, I used over 400,000 positions from 5,700 games at rating levels from Elo 1600 to 2700 only, all run on my office and home PCs. Below Elo 2000 the available data was so scant that noise is evident in the paper’s table.
Since then, many more games by lower-rated players are being archived—much thanks to the greater availability of chessboards that automatically record moves in the standard PGN format, and to an upswell in tournaments, for youth in particular. Last year, thanks to the great free bandwidth granted by my university’s Center for Computational Research (CCR), I took data in the quicker mode from over 10,600,000 moves from just over 400,000 game-sides (counting White and Black separately) in every tournament compiled by ChessBase as well as some posted only by The Week in Chess (TWIC) or provided directly by the World Chess Federation (FIDE). My two main test quantities are:
- The percentage of the computer’s best move being the one the player chose (“MM%”).
- The average error judged by the computer per move, scaling down large differences (“ASD”).
My 2011 paper found strong linear relations of these quantities to the players’ rating, and great ASD fits on a 3-million-move data set are shown graphically in this post. With MM% and my new 2018 data, here is what I see when I limit to the 1600–2700 range, grouping in “buckets” of 25 Elo points. All screenshots are taken with Andrew Que’s Polynomial Regression applet. They all show data taken with Stockfish 9 run to search depth at least 20 and breadth at least 200 million nodes; the similar data for the chess program Komodo 11.3 gives similar results.

Even with vastly more data, there still does not appear any reason to reject the simple hypothesis that the relation to rating is linear. Not only is 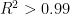
But now I have over 14,000 moves in individual buckets clear down to the FIDE minimum 1000 rating; only the 2750 bucket with 11,923 moves and the 2800-level bucket with 6,340 (from just a handful of the world’s elite players) lag behind. When those buckets are added, here is what we see:

The linear hypothesis is notably less tenable. Instead, a quadratic polynomial fits supremely well:

Thus it seems I must admit a nonlinearity into my chess model. This may not be just about slightly improving my model’s application to players at the ends of the rating spectrum. Philosophically, nonlinearity can be a game-changer: the way Newtonian physics is fine for flying jets all around the globe but finding your neighbor’s house via GPS absolutely requires Einstein.
The Horizon Issue
Let us flip the axes so that 



Having the rating of perfect agreement be about 1950—which is a amateur A-level in the US—is ludicrous. The greater import is how the increase stops at Elo 3000 with matching just under 75%. The serious implication I draw is that this helps locate the horizon of effectiveness of the data and my methods based on it. Meanwhile, I’ve had the sense from applications that my full model based on smaller higher-quality data is coherent up to about 3100 but cannot tell differences above that.
Indeed, there is a corroborating indicator of this horizon: The top chess programs, or even different (major) versions of the same program, don’t even match each other over 75% with regularity. Moreover, the same program will fairly often change to a different move when left running for more time or to a greater search depth. If it didn’t change, it wouldn’t improve. Thus my tests, which have no foreknowledge of how long a program used to cheat was running and on how powerful hardware, cannot expect to register positives at a higher rate. The natural agreement rates for human players range from about 35% for novices to upwards of 60% for world champions.
The Average-Error Case
The fit to average scaled error-per-move (ASD) shows the other side of the horizon issue. The ASD measure is more tightly correlated to rating—as the graphs in the above-mentioned post suffice to indicate. Here is the corresponding graph on the new data, again with flipped axes:

Only under 1250 Elo does perfect linearity seem to be countermanded. The issue, however, is at the other end. Committing asymptotically zero error seems to be a more acute indicator of perfection than 100% agreement with a strong program. However, the
One can move from the above indication of my setup losing mojo before 3000 to allege that it is insufficient for fair judgment of human players above 2500, say, so that the intercept is not valid. My counter-argument is that the same intercept is also a robust extrapolation from the range 1500 to 2500 where the linear fit is nearly perfect and the computer’s sufficiency for authoritative judgment of the players is beyond doubt.
Nevertheless, the above “game-changer” for the move-matching percentage suggests the same for ASD. A quadratic fit to ASD produces the following results:

Now the 
One More Riff
Let us think of move-matching for a given rating 





Well, 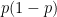
Recovering 




Open Problems
We’ve connected the horizon of perfect play to whether the fundamental relationship of rating to agreement with strong computer programs is linear, quadratic, or indirectly cubic. Which relationship is true? What further tests may best ascertain the range of effectiveness of inferences from these data?
Update (21 July 2023):
FIDE has published a report by Jeff Sonas with evidence that ratings below 2000 are deflated by amounts that grow to 400 Elo at the 1000 rating floor. The report advocates simply mapping 

The conversion formula implied by these curves (please excuse excess precision) is:

This agrees with Sonas’s curve well within error bars at the ends: it maps 1000 to 1385 rather than 1400 and 2000 to 2018 which is almost stasis. In the middle it is lower by 40-to-50 Elo, e.g. 1300 goes to 1529 rather than 1580, 1500 to 1647 rather than 1700, and 1700 to 1783 rather than 1820.
These differences from the Sonas proposal may not be significant even in the middle, and the most immediate point is broad agreement with the (drastic) proposed magnitude of the changes. Put a different way, Sonas’s proposal—and the measurements and simulations he uses to justify it—are much in line with the view that the relationships described in this post on the whole should be linear. The most fundamental issue I see right now is whether this should be so.
And for one side comment, with a view toward opening FIDE ratings to players of skill that I measure below 1000 on the current scale, this may support arguing 1200 rather than 1400 as the new rating floor.


To me, the right half of illustration #4, where the increase of MM% would make the rating decrease, is evidence that the quadratic fit is an accident without real meaning. I would try to fit e.g. a logistic function to your data instead.
Thanks. Yes, that is immediately sensible. In fact, I moved my screening formula to use a cubic curve, which has a similar S-shape in the region of concern, and did something analogous with my Intrinsic Performance Rating formula in my full model. Outside the region, it remains unclear to me which curve is better, and …
…This matter may all be superseded by observations of Jeff Sonas which FIDE published today (direct link to 19-page report). These pass one immediate “sniff test”—if you take diagram 3 in this post with the quadratic fit, and superpose a linear fit of the data from Elo 2000 to 2800 only, the difference between the lines widens to about 400 Elo at the bottom of the figure (for Elo 1000), and the “correction” from the quadratic curve to the linear one is close to his proposed “compression formula” below Elo 2000.
It’s possible that players with Elo ratings near 1000 tend to be improving (because they are mostly children or beginners). If that’s the case, then because the Elo rating is a weighted average of past performances, the Elo rating for these lower rated players will tend to underestimate their actual current playing strength. This in turn means that these players will more frequently choose the computer’s best move than anticipated.
it would be really neat if someone would create a tool to explore the scientific “citation graph” interactively. think google ought to do the same thing for their search engine results/ indexing. pages of results is really a pretty rudimentary interface that hasnt changed much in 2 decades. theres gotta be other/ better ways to explore the “information cloud” etc…