Depth of Satisficing
When and why do people stop thinking?

Tamal Biswas has been my graduate partner on my research model of decision-making at chess for over four years. He has I believe solved the puzzle of how best to incorporate depth into the model. This connects to ideas of the inherent difficulty of decisions, levels of thinking, and stopping rules by which to convert thought into action.
Today I describe his work on the model and the surprise of being able to distinguish skill solely on cases where people make mistakes. This is shown in two neat animations, one using data from the Stockfish 6 chess program, the other with the Komodo 9 program, whose elements are explained below.
Tamal presented this work on the Doctoral Consortium day of the 2015 Algorithmic Decision Theory conference in Lexington, Kentucky. The conference was organized and hosted by Judy Goldsmith, whom I have known since our undergraduate days at Princeton. The consortium was organized by Esra Erdem and Nick Mattei jointly with the co-located LPNMR conference. Our full paper, “Measuring Level-K Reasoning, Satisficing, and Human Error in Game-Play Data,” will be presented at the 2015 IEEE Conference on Machine Learning and its Applications in Miami. Tamal presented our predecessor paper, “Quantifying Depth and Complexity of Thinking and Knowledge,” at the 2015 International Conference on Agents and AI in Lisbon last January.
Although we have blogged about the chess research several times before, I haven’t yet described details of my model here. After doing so we’ll see why depth has been tricky to incorporate and what our new discoveries mean.
The Data
The only connection to chess is that chess has alternating turns involving decisions whose options can be given numerical utility values that are objective and reliable but difficult for the players to discern. The numbers come from powerful chess programs (commonly called engines) whose rated playing skill long surpasses that of human players and is arguably measurably close to perfection. The Elo rating system is scaled so that a difference of 100 rating points derives from and predicts a 64%-to-36% points margin for the stronger player. The World Chess Federation lists over 20,000 human players above the 2200 threshold for “master” but only 45 players above 2700 and just four above 2800 including world champion Magnus Carlsen at 2850—while the best engines are rated above 3200 and my model currently suggests a ceiling below 3500.
The move values are updated by the program in rounds of increasing search depth 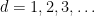

The numbers come from chess factors—beginning with basic values for the pieces such as pawn = 1, knight = 3, and so on—but they are governed by a powerful regularity. Position values are centered on 0.00 meaning “even chances,” positive for advantage to the side to move, and negative for disadvantage. The regularity is that when the average score (counting 1 per win and 0.5 per draw) achieved by players from positions of value 

The factor 

A 2012 paper by Amir Ban not only observes this relationship (also separating out wins and draws) but argues that generating evaluations within the search that follow it optimizes the strength of the engine. We henceforth argue that the utility values have organic import beyond chess, and that the problem addressed by our model is a general one of “converting utilities into probabilities.”
By the way: Ban is famous for being a co-creator of both the Deep Junior chess program and the USB flash drive. That is right: the flash drive that we all use, every day, to store and transfer information—probably a bit more impactful than anything to do with chess, but amazing that he did both.
The Model and Depth
The model uses the move values together with parameters denoting skills of the player to generate probabilities 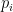
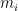



where 


Chess has a broad divide between “positional” and “tactical” skill. I’ve regarded
My first idea was to model depth as a random variable with a player-specific distribution. As a player I’ve had the experience of sometimes not seeing two moves ahead and other times seeing “everything.” A discrete distribution 

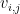



A related idea was to compute probabilities 
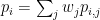
Doing so changed the regression from one over 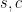
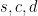

The Depth is in the Data
Looking back, I think my idea was wrong because depth is not primarily a human property. We don’t first (randomly) choose each time whether to be deep or shallow—to be a Fischer or a “fish” for a move. Instead, aspects of the position influence how deep we go before being satisfied enough to stop. One aspect which I had conceived within my 
A move involving a sacrifice might look poor until quite far into the search, and then “swing up” to become the best move when its latent value emerges. A “trap” set by the opponent might look tempting enough to be valued best at first even by the engines, but they will eventually “swing down” the value as the point of the trap is plumbed. The sublime trap that did much to win the 2008 world championship match for Viswanathan Anand over Vladimir Kramnik shows both phenomena:

|
|
Left: Position before Kramnik’s 29.Nxd4. Right: Anand’s winning 34…Ne3! riposte. Below: Stockfish 6 values x100 at depths 1–19. |

Kramnik’s 29.Nxd4 capture might be dismissed by a beginner since Black’s queen can just take the knight, but a seasoned player will see the followup 30.Rd1 skewering Black’s queen and knight on d7. Evidently this looked good to Kramnik through 30…Nf6 31.Rxd4 Nxg4 32.Rd7+ Kf6 33.Rxb7 Rc1+ 34.Bf1 coming out a pawn ahead, and Stockfish turns from negative to positive throughout depths 9–14. But then it sees the shocking 34…Ne3!!, when after 35.fxe3 fxe3 Black’s passed pawn is unstoppable. Kramnik never saw these moves coming and resigned then and there.
In my old view, Kramnik pulled a number between 9 and 14 out of his thinking cap and paid the piper to Anand who had rolled 16 or higher at his previous turn. Based on the good fits to my two-parameter model, the reality that most positions are clear-cut enough even for beginners to find the best move over 40% of the time, and reasoning about randomness, I pegged the phenomenon as secondary and likely offset by cases where the played move “swung up.”
In Tamal’s view the whole plateau of 9–14 put friction on Kramnik’s search. Once Kramnik was satisfied the advantage was holding, he stopped and played the fateful capture. Of various ways to quantify “swing,” Tamal chose one that emphasizes plateaus. Then he showed larger effects than I ever expected. Between the 0.0–1.0 and 4.0–5.0 ranges of “swing up” for the best move in his measure, the frequency of 2700-level players finding it plummets from 70% to 30%. This cannot be ignored.
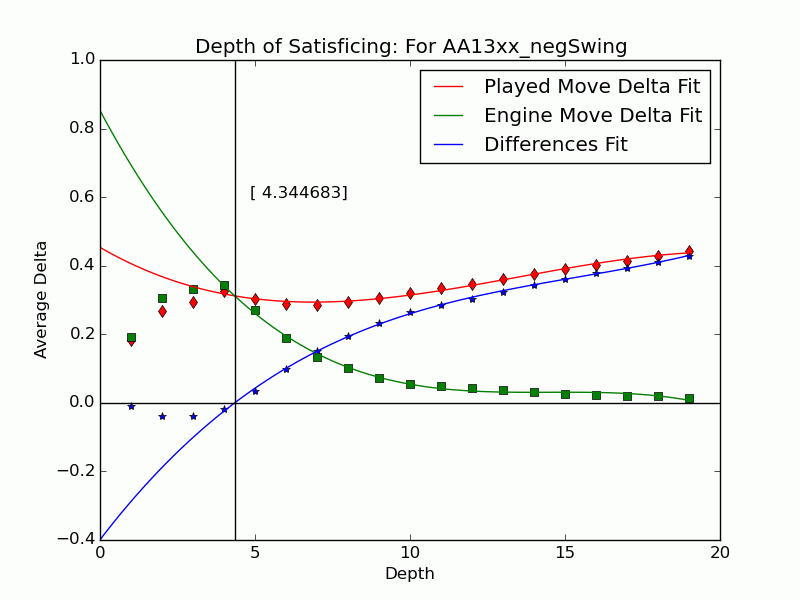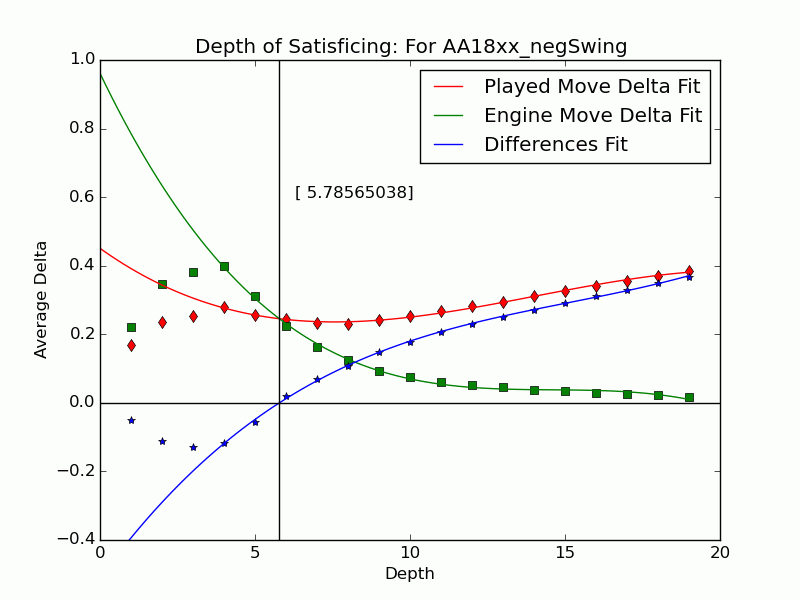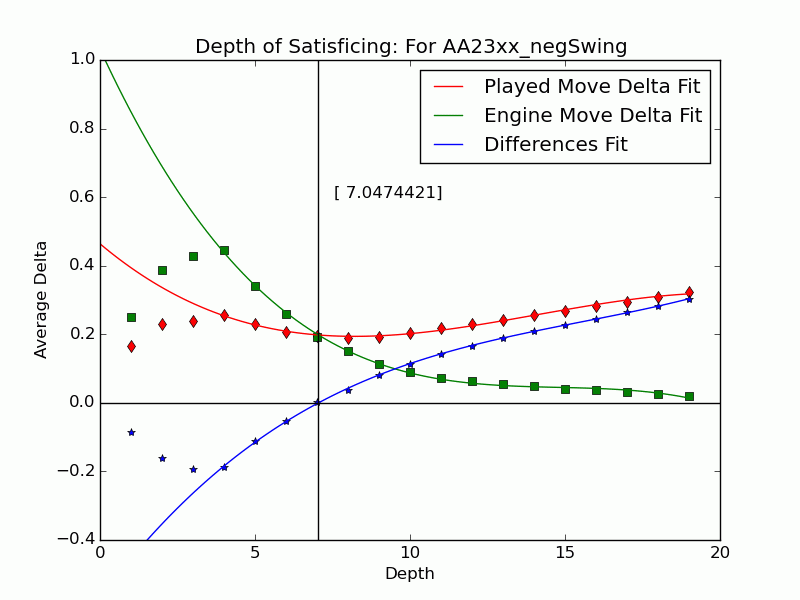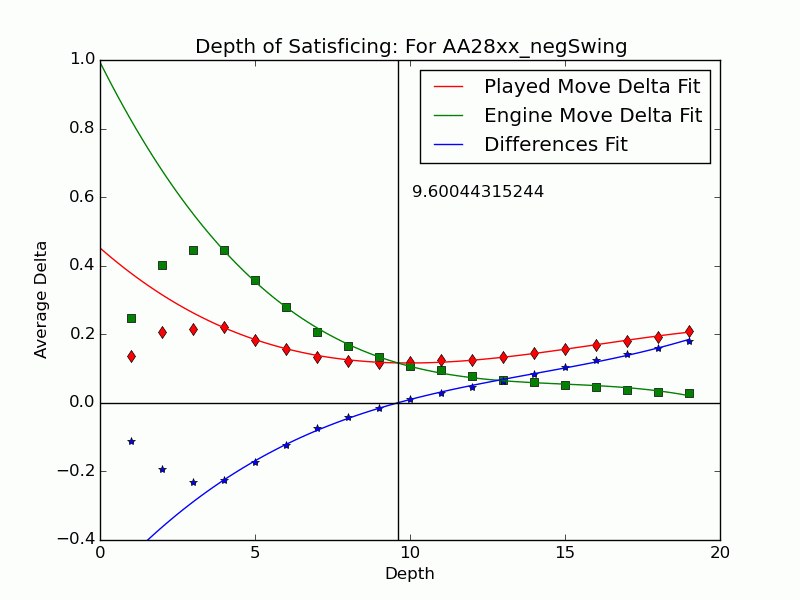
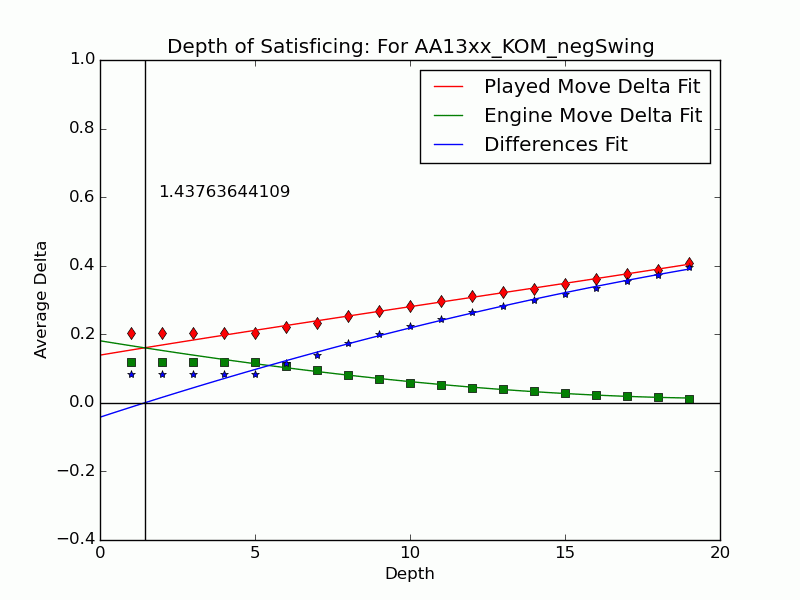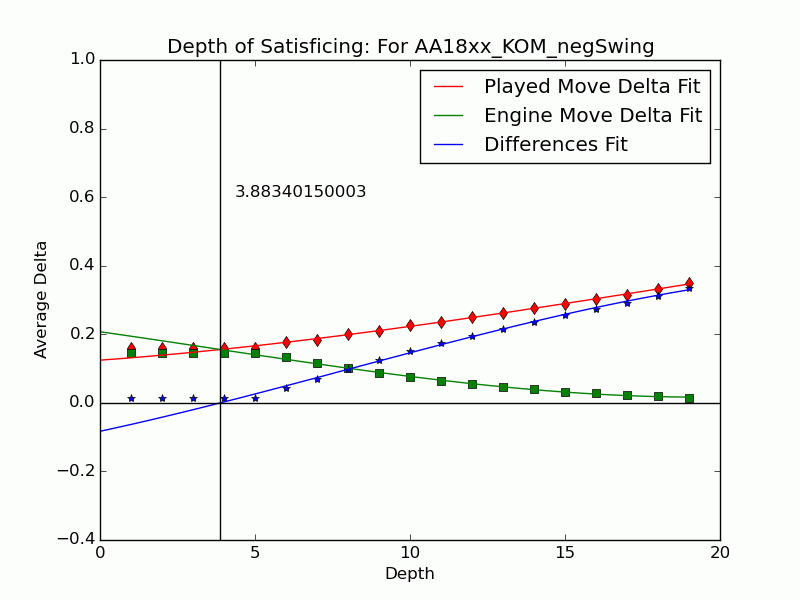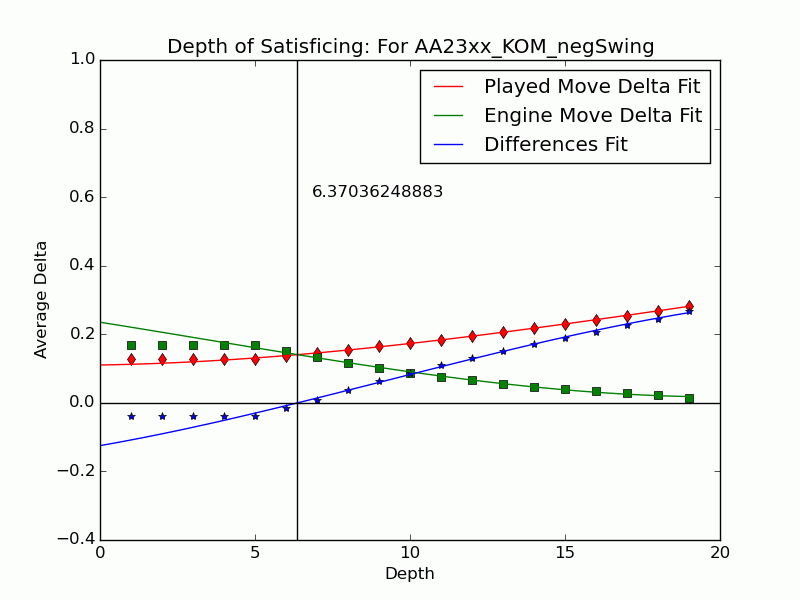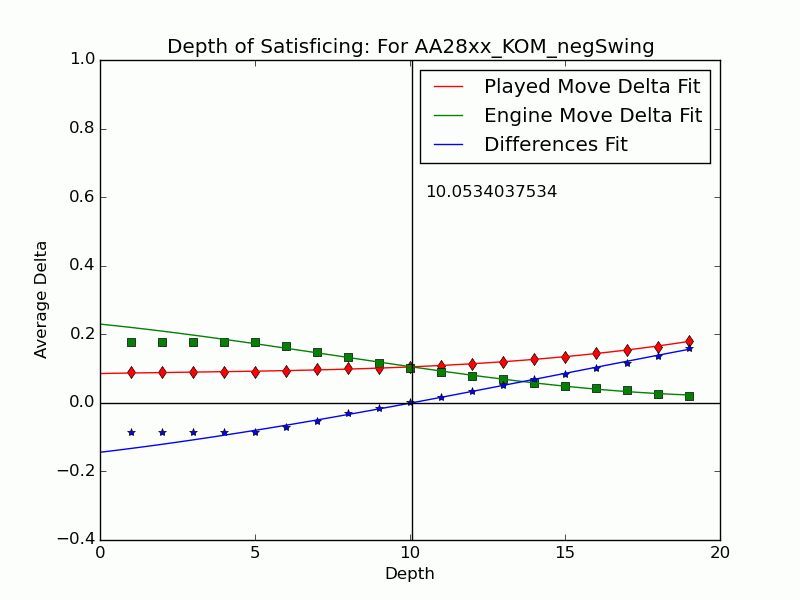
Depth of Satisficing
This result presaged the effectiveness of several other measures formulated in our ICAART 2015 paper to represent the complexity and difficulty of a decision. We introduced some ideas relating to test-taking in an earlier post but now we’ve settled on metrics. The most distinctive of Tamal’s ideas blends our investigation of depth with Herbert Simon’s notion of satisficing going back to the years after World War II.
Simon coined satisficing from “satisfy” and “suffice” and contrasted it to optimizing during a search. It is often treated as a decision policy of meeting needs and constraints, but Simon also had in mind the kind of limitation from bounded rationality (another term he coined) that arises in searches when information is hard to find and values are hard to discern. In a zero-sum setting like chess, except for cases where one is so far ahead that safety trumps maximizing, any return short of optimum indicates an objective mistake. We address why players stop thinking when their move is (or is not) a mistake. We use the search depth
Not all inferior moves 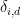
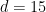

We can extend the notion to include the many negative-swing cases where the played move 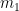




Using UB’s Center for Computational Research (CCR) to run the engines Stockfish 6 and Komodo 9, we have analyzed every published game played in 2010–2014 in which both players were within 10 Elo points of a century or half-century mark (widened to 15 or 20 for Elo 1300 to 1650, 2750, and 2800 to keep up the sample size). Combining Elo 1300 and 1350, 1400 and 1450, etc., shows that the crossover depth grows steadily with rating in both the GIF for Stockfish (left) and the GIF for Komodo (right).


There we have it: a strong correlate of skill derived only from moves where players erred. The inference is that better players make mistakes whose flaws require more time and depth to expose, as measured objectively by the engines. A further surprise is that the satisficing depths go clear down near zero for novice players—that we got anything regular from values at depths below 4 (which many engines omit) is noteworthy. That the best players’ figures barely poke above depth 10—which computers reach in milliseconds—is also sobering.
Depth and Time
Chess is played with a time budget, much as one has when taking a standardized test. The first budget is almost always for turns 1–40, and although exhausting it before move 40 loses the game immediately, players often use the bulk of it by move 30 or even 25. The following moves are then played under “time pressure.” Segregating turns 9–25 from 26–40 (the opening turns 1–8 are skipped in the analysis) shows a clear effect of free time enhancing the depth and time pressure lowering it:

All of these games—this data set has over 1.08 million analyzed moves from over 17,500 games—come from recent real competitions, no simulations or subject waivers needed, in which skill levels are reliably known via the Elo system. Data this large, in a model that promotes theoretical formulations for practical phenomena, should provide a good standard of comparison for other applications. Tamal and I have many further ideas to pursue.
Open Problems
What parallels do you see between the thought processes revealed in chess and decision behaviors in other walks of life?
[added note on consortium organizers to intro, fixed Nxe3 in caption to Ne3]
Trackbacks
- Rankings Versus Ratings | Gödel's Lost Letter and P=NP
- October Links and Activities | Mental Wilderness
- A Chess Firewall at Zero? | Gödel's Lost Letter and P=NP
- A Chess Firewall at Zero?
- Unskewing the Election | Gödel's Lost Letter and P=NP
- Magnus and the Turkey Grinder | Gödel's Lost Letter and P=NP
- Stopped Watches and Data Analytics | Gödel's Lost Letter and P=NP
- Sliding-Scale Problems | Gödel's Lost Letter and P=NP
- London Calling | Gödel's Lost Letter and P=NP
- Far From a Turkey Shoot | Gödel's Lost Letter and P=NP
- Predicting Chess and Horses | Gödel's Lost Letter and P=NP
- A Talk at TTIC on Experiment Design | Gödel's Lost Letter and P=NP
- Daniel Kahneman, 1934–2024 | Gödel's Lost Letter and P=NP


{kind=link}
{kind=link}
Question about the logistic plot in the beginning: shouldn’t the green and blue plot be perfectly symmetrical? Each game someone faces a 150 higher, that other player faces a 150 lower.
Or are the plots only for white players?
Perceptive question. The points are only for the player to move. The plot comes from this paper, which has other plots showing that in positions of any value v, the player to move has 2-3% lower expectation than the opponent. The effect is absent in games played by computers. The reason appears to be nothing more than the player to move having the first opportunity to make a game-determining blunder.
These terrific Gödel’s Lost Letter and P=NP (GLL) questions can be linked to the computer science literature more easily (by me anyway) if we substitute for the broad term “thought” the trendy technical term “computational elaboration.”
The comment that follows (as a separate post) can then be read as an chess-inspired accompaniment and continuation to two recent comments on Sthetl Optimized (see #64–65 of “Six Announcements” of September 21, 2015).
In aggregate these three comments are an extended meditation — with plenty of student-friendly references — upon the central role that computational elaboration is assuming, in STEAM performative arts as various as chess, theorem-proving, small-s quantum skepticism, and 21st century systems engineering.
My appreciation and thanks are extended to Ken Regan and Tamal Biswas, for demonstrating so convincingly that chess affords a marvelous venue for in-depth scholarly study of the ubiquitous 21st century phenomenon of computational elaboration. Surely many further illuminations can be had by continuing these chess studies. Appreciation and thanks are extended also to Scott Aaronson’s Shtetl Optimized, for graciously hosting two earlier comments. And thanks are extended to everyone (including commenters) for sustaining these outstanding forums.
Remarks on Elaboration III
Elaborate resources Technically minded GLL readers can find student-friendly introductions to the notion of elaboration at Microsoft Research’s interactive GitHub tutorial “The Lean Theorem Prover”, and philosophically minded GLL readers can find a student-friendly survey on Lean-collaborator (and philosopher/mathematician) Jeremy Avigad’s home page, as his delightfully elaborative preprint “Mathematics and language.”
First conclusion: the Wittgenstein-Knuth connexion Mathematical philosophy (in the sense of Wittgenstein) is becoming a performative science (in the sense of Knuth).
The quantum connexion A natural connexion with quantum information theory arises when we wonder: “As mathematical research becomes computationally elaborative … what other STEM disciplines can similarly become computationally elaborative?” For our small quantum systems engineering (QSE) group up in the Pacific Northwest, one answer is quantum transport theory … and our evolving seminar notes — whose most up-to-date release can always be read by clicking on my name above — describe some of the practical implications of Gil Kalai’s small-s quantum skepticism for implementing this computationally elaborative program.
Historical elaboration Needless to say, we are not the first to make these elaborative connections. Back in the mid-1990s, DARPA/NRO’s Dennis Healy (now deceased) foresightedly supported what we would today call computational elaboration in the photonic simulation package “Meep” (DARPA/NRO N00014-05-1-0700 and NSF DMR-9400334), and NRO’s research investment in computational elaboration continues today in the MURI program “Homotopy Type Theory: Unified Foundations of Mathematics and Computation” (HoTT), which supports Jeremy Avigad’s research, among others (Google finds plenty of Meep and HoTT resources).
Computationally performative imagination and ingenuity As Dennis Healy put it in a 2007 lecture (shortly before his passing):
Second conclusion: the Kalai connexion Quantum small-s skepticism (in the mathematical sense of Gil Kalai) is evolving to provide crucial foundations for computationally elaborative science and engineering (in the traditional STEM-sense of Wittgenstein/Knuth/Healy).
An opening question In disciplines as disparate as chess, mathematics, and engineering, is the highest-level creativity destined to become the domain of centaurs, that is, human imaginations performatively amplified by computational elaboration? Ken Regan’s pioneering cognitive research speaks directly to this question
Third conclusion: the centaur elaboration Plenty of folks *(Ken Regan and Tamal Biswas for example, and me too) appreciate that elaborative centaurs already are exhibiting the highest levels of creativity in chess and presumably many of disciplines (market trading, for example) … and not everyone is happy with the implications.
As just one sobering question among many, what becomes of good economies — good in the enlightened Jeffersonian sense — when their most performative actors are irretrievably evolving to be not human polities, but elite computational centaurs?
Concluding elaboration We are all of us already enrolled as the subjects of an all-encompassing global experiment in computational elaboration, in which, as Ken Regan’s GLL essay “Depth of Satisficing” reminds us, there are no subject waivers.
As a concluding confection, literature-minded readers of Gödel’s Lost Letter will find that Ted Chiang’s Nebula Award story Story of Your Life (1998) presages multiple themes that are associated to the performative language of elaboration.
Indeed Chiang’s story resorts to technical language to make this point explicit:
As we now appreciate, this is what computer languages do already … and isn’t this what proponents of computational elaboration seek to extend throughout the STEAM literature?
Conclusion Ted Chiang’s Story of Your Life (1998) reads naturally as an foresighted story about the capacity of performative elaboration to reshape human cognition … as with all first-rate speculative fiction, it is unsurprising that Chiang’s vision is now coming true.
No chess players will be surprised either: in chess the middle game has always been implicit in the opening, and end game implicit in the middle game; the 21st century’s emerging tools for computational elaboration are merely extending Chiang’s principle of performative transformation throughout the STEAM literature.
It is interesting that the logistic curve and the normal CDF are quite close. 1/(1+e^{-2x}) differs by at most 0.044 and 1/(1+e^{-ax}) with a = 4/sqrt(2 pi), which matches the CDF’s slope at the origin, differs by at most 0.017. Maybe those logistic curves are normal distributions.
Thanks—this is a deep matter, and of course your comment goes to Amir Ban’s paper as well. The same normal/logistic issue plays out in the Elo rating system—Wikipedia acts as a good stem page here. The USCF switched to logistic; FIDE officially uses a discrete table lookup. A 1-2% change could usefully improve the tuning of my model. Here’s a further numerical issue which I’d like to ask about, technically coming from the closely related hyperbolic tangent rather than logistic:
Morph it by substituting the approximation . You get
. You get
What is the name of this function? The fact that a and v are now separated is part of the issue.
It comes about—with a probability p in place of v and a dimensionless u in place of a, both subscripted by i for the i-th move—if I use a ratio of (things closely related to) logits rather than log-probabilities (and rather than probits) on the other side of my model’s main equation—which I stopped short of including to keep the length of this post down.
Erratum (?), takes
takes  to
to
Ah—eagle eye; it’s not the same after cross-multiplying. I actually used too. Anyway, the form I chose looks more analogous to tanh to me. The difference matters in the “tails” and I wonder where I might be able to find some general interpretation of it.
too. Anyway, the form I chose looks more analogous to tanh to me. The difference matters in the “tails” and I wonder where I might be able to find some general interpretation of it.
Either way, my main goal is to congratulate you and Tamal for a marvelous study whose conclusions (as it seems to me) have implications that reach far beyond the chess-world.
Thanks very much—we continue working on bringing those implications out. The two functions differ by a trice, always interesting new things to probe…
In some cases there are intermediate “only” moves that extend the depth of the branch being analysed (e.g. Kasparov-Topalov 1999), typically where a series of checks is present (which might be correlated with sacrificial moves).
Indeed, that often shows up in the extension search. I figure the engines and humans “roll with it”—the engine still searches deeper at the next ply of depth, and the humans might (less easily) see those moves with less exertion.
There was recently a Kaggle competition to guess the strength of a player based on a single game. Can this technique outperform the winner of that competition?
Thanks—I knew about it a year ago but we were occupied doing programming for FIDE thru last February and didn’t have the scripts to leverage CCR’s power (thankfully Stockfish and Komodo have Linux versions) done until this summer. One hesitation is that my IPR error bars are huge for just one game. You’ve prompted us to think that the ideas in this post may combine with IPR to narrow them.