Who Invented Pointers, Amortized Complexity, And More?
Some algorithmic tricks were first invented in complexity theory

Andrey Kolmogorov, Fred Hennie, Richard Stearns, and Walter Savitch are all famous separately; but they have something in common. Read on, and see.
Today I wish to discuss some algorithmic tricks and show that they were initially used by complexity theorists, years before they were used by algorithm designers.
To steal a phrase: it’s computational complexity all the way down. Well not exactly. The situation is slightly more complex—a bad pun. The complexity theorists often invented a concept and used it in a narrow way, while later it was rediscovered and made a general notion. This is another example of the principle: The last to discover X often gets the credit for X. I note that the dictionary gets this wrong:

Its not the first but the last. For after the last gets the credit, it’s no longer a “discovery.” Let’s look at three examples of this phenomenon.
Pointers
Who invented it? Andrey Kolmogorov in 1953.
Who really invented it? Harold Lawson in 1964.
Details: Kolmogorov did so much that one should not be surprised that he invented “pointers.” In 1953 he wrote a short paper, really an abstract, “To the Definition of an Algorithm.” This later became a 26-page paper joint with the still-active Vladimir Uspensky. In that and the preceding decades, several researchers had advanced formal notions of an algorithm. Of course we now know they all are the same, in the sense they define the same class of functions. Whether one uses Turing machines, recursive functions, or lambda calculus—to name just a few—you get the same functions. This is an important point. In mathematics, confidence that a definition is right is often best seen by showing that there are many equivalent ways to define the concept.
Kolmogorov’s notion was similar to a Turing machine, but he allowed the “tape” to be an almost arbitrary graph. During the computation, in his model, the machine could add and change edges. How this and other models constitute a “Pointer Machine” is discussed in a survey by Amir ben-Amram. A beautiful explanation of Kolmogorov’s ideas is in the survey: “Algorithms: A Quest for Absolute Definitions,” by Andreas Blass and Yuri Gurevich. I quote from their paper:
The vertices of the graph correspond to Turing’s squares; each vertex has a color chosen from a fixed finite palette of vertex colors; one of the vertices is the current computation center. Each edge has a color chosen from a fixed finite palette of edge colors; distinct edges from the same node have different colors. The program has this form: replace the vicinity U of a fixed radius around the central node by a new vicinity W that depends on the isomorphism type of the digraph U with the colors and the distinguished central vertex. Contrary to Turing’s tape whose topology is fixed, Kolmogorov’s “tape” is reconfigurable.
Harold Lawson invented pointers as we know them today in 1964. He received the IEEE Computer Pioneer Award in 2000:
for inventing the pointer variable and introducing this concept into PL/I, thus providing for the first time, the capability to flexibly treat linked lists in a general-purpose high level language.
The idea that a pointer can be variable was by Kolmogorov, and distinct from fixed pointers in Lisp implementations as Ben-Amram notes, but making it a syntactic variable in a programming language made the difference.
Amortized Complexity
Who invented it? Fred Hennie and Richard Stearns in 1966.
Who really invented it? Robert Tarjan in 1985.
Details: Hennie and Stearns proved one of the basic results in complexity theory. Initially Turing machines had one tape that was used for input and for temporary storage. It was quickly realized that one could easily generalize this to have multiple tapes—some for input, others for temporary storage. This does not change the class of computable functions. That is stable under such changes. But it does change the time that such a machine takes to compute some task. What they proved is that the number of tapes was relatively unimportant provide there were at least two. More precisely they proved that a machine with 
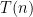
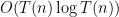
This result is very important and fundamental to the understanding of time complexity. The simulation is also very clever. Even for simulating three tapes by two, the issue is that the obvious way to do the simulation seems to require that the time increase from 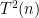
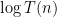
Bob Tarjan years later used the same fundamental idea in what is called amortized complexity. Bob’s ideas explained in his 1985 paper Amortized Computational Complexity made a useful formal distinction within the concept of an operation being good on average. The distinction is whether the operation can possibly be bad all the time, in highly “unlucky” cases. If you are finding the successor of a node in a binary search tree, you might unluckily have to go all the way up the tree, and all the way back down on the next step. But the step after that will be just one edge, and overall, the entire inorder transversal of 
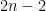

Meet in the Middle
Who invented it? Walter Savitch in 1965.
Who really invented it? Whitfield Diffie and Martin Hellman in 1977.
Details: The most famous example in computational complexity is certainly Savitch’s brilliant result—still the best known—showing that nondeterministic space 
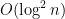



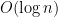
A journey of a thousand miles has a step that is 500 miles from the beginning and 500 miles from the end.
Diffie and Hellman in 1977 created the idea of using this method for an attack on a block cipher. Their attack largely deflates the idea that a composition of encryptions
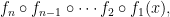
where each 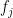






If we had 
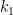



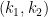
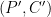
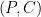
Open Problems
Okay, not all algorithmic ideas started in complexity theory. But a number of very important ones did. All three that we’ve covered in fact came from analyzing basic models of computation. Can you name some others?


For a concrete example of the definition in the Introduction, consider defining the “Novelty” move in a chess game. You might think it should be the first move in the game that creates a position that has never been played before—at least according to databases of the entire historical record of chess games. However, in many cases—indeed in cases I’ve encountered in conducting my formal statistical tests—the game flips back into known channels on the next move. This means a case where one order of playing out two moves is usual but the other order didn’t hurt. Hence the “Novelty” is better defined as the last move in a game that takes it from a position known from initial segments of previous games into an unknown position.
For example, in the basic Najdorf Sicilian 1. e4 c5 2. Nf3 d6 3. d4 cxd4 4. Nxd4 Nf6 5. Nc3 a6, after 6. Be3 Ng4, it evidently wasn’t realized until 1992 that 7. Bc1!? by White is not a terrible loss of tempo. Black has nothing really better than retreating the exposed Knight with 7…Nf6, whereupon White can do something else, having gained the knowledge that Black didn’t play one of the alternatives to 6…Ng4 which White might have liked facing. Indeed the first such game, in 1993, continued 7. Bc1 Nf6 8. Bg5 e6 9. f4!? Qb6!?, entering the famous “Poisoned Pawn” variation in which Fischer and Spassky and many others battled of yore. Hence it would be unhelpful to consider either 7.Bc1 or 7…Nf6 “novel” in that game.
Reblogged this on rvalue and commented:
Interesting!
Reductions: first in complexity, latter (udi manber book) a design technique
Dear Dick (and Ken),
While I consider Savitch’s theorem a most fundamental result, and he fully deserves the credit for it, one should credit the underlying idea of “Meet in the Middle” to Philip Lewis, Juris Hartmanis and Richard Stearns, to their paper “Memory bounds for recognition of context-free and context-sensitive languages”.
In fact you had a beautiful blog on exactly this:
http://rjlipton.wordpress.com/2009/04/05/savitchs-theorem/
——–
As to the one comment just above, by André Vignatti, much as I would like to claim credit for complexity theorists :-), I think the idea of a reduction as used in complexity theory most definitely and directly comes from recursion theory. But I am sure the more general idea of reducing one problem to another came much earlier, probably lost in antiquity. Perhaps one should not think too much along such lines, or we get reductio ad absurdum (or is there a self-referential pun somewhere?)
Jin-Yi
That’s because they’re the same group of people wearing two hats. Sometimes they’re astronauts, other times they’re cosmonauts.