More Quantum Chocolate Boxes
Unwrapping the layers between classical and quantum?

Daniel Simon discovered the first quantum algorithm that yielded an oracle separation of 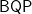
Today we wish to revisit the question of solving Simon’s problem by a classical algorithm. We also ask whether the classical algorithms are being given a fair counterpart to the following principle, which the quantum algorithms take for granted:
Given an invertible function, there is a unitary matrix that implements the function as a permutation matrix, and moreover: the matrix is efficiently constructible, in a way that is realizable by a physical system.
Let’s call this the quantum black box assumption (QBB). Without it there is no Deutsch(-Jozsa) or Simon or Grover algorithm, and in the details, no Shor algorithm either (compare discussion here). Without it there are no quantum algorithms for anything interesting, since it is a central assumption required by all them. It is justified by polynomial-time universality theorems for quantum circuits, but is it really innocuous? And since the matrix computes the function at any algebraic input, should not the representation for the classical algorithms do the same?
Ironically, Simon himself is not sanguine on the prospects of quantum computers. He works on Windows security at Microsoft, and was among the many builders of the Transport Layer Security (TLS) protocol. In March 2009 he contributed comments noted here, including this statement:
Basically, there is one thing that quantum computers [are known to do] better than classical computers. Because this one thing happens to lead to polynomial-time algorithms for integer factoring and discrete log, quantum computers have been bandied about as an incredible new computing technology, but the truth is that this one thing is really very limited in scope, and in a decade and a half, nobody’s found another significant application for it.
Moreover, there are lots of (admittedly informal) reasons for believing that quantum computers can’t really do anything interesting beyond this one thing.
Simon would add, following the title of his own blog, “I could be wrong.” We could be wrong likewise, but let’s first look at Simon’s problem.
Simon’s Distinguishing Problem
We describe Simon’s problem with the same chocolate-box metaphor we recently used here. Again we are trying to identify a Boolean function 
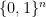


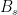

![\displaystyle B_s = \{f: (\forall x,y)[f(x) = f(y) \iff y = x \oplus s]\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++B_s+%3D+%5C%7Bf%3A+%28%5Cforall+x%2Cy%29%5Bf%28x%29+%3D+f%28y%29+%5Ciff+y+%3D+x+%5Coplus+s%5D%5C%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
As usual 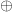


The input to Simon’s problem is an oracle 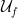

As in our previous post, 


Some Basics
The key to understanding a quantum algorithm is to look at the vectors and unitary operators. All in this case are from real Hilbert spaces, or if you prefer finite dimensional Euclidean spaces. We will use capital letters for our vectors, and script letters for our matrices. We also avoid subscripts and use the simple notion 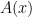
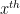

The Hadamard matrix is denoted by 

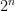

to denote the row 


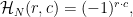
where 


Simon’s Quantum Algorithm
The first key insight is that we can use a quantum algorithm to efficiently construct a vector

when 



Then we can apply the matrix 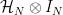


This is what is meant by applying the Hadamard only to the
We need to analyze what the amplitude is of the coordinates 
-
In this case
values the only time
is non-zero is when
. This only happens once, and therefore
Thus any measurement of
to
rather than numbers, after
-
In this case
. If it has a pre-image
it also has a pre-image
. In this case
This is either
or
depending on whether or not
. This gives an equation on
equations by which to solve for


Quantum Versus Classical Settings
All discussions of Simon’s algorithm immediately point out that there is no classical algorithm that can solve the problem without an exponential number of calls to the black box for
Well of course that is not quite true. If the black box for 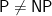
We suggest that the proper comparison may involve granting the classical setting a multi-linear extension 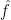


Child 1: “Where did you get that missile?”
Child 2: “Well, where did you get that tank?”
The Classical Black Box Assumption
To make our assumption concrete, we settle on this extension of a Boolean function 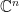
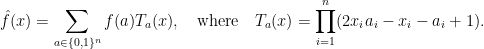
That is, 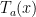



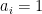
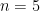


The effect is that over Boolean arguments 
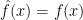
Of course for other arguments
Given a function
with a polynomial size Boolean circuit, there is an arithmetic circuit that is also polynomial in size and computes
.
This assertion itself does not force 
And for a companion question, is the QBB assumption really true in prospect? Why is it fair to have a quantum linear operator that can be applied to other quantum states besides the 0-1 basis states, and not be able to do so with a classical multi-linear extension? Or is this where the first power of quantum over classical resides?
Using CBB for Simon’s Problem
Can we use the CBB assumption to create a classical algorithm for Simon’s problem? We would like to report that the answer is yes, but we leave it open. It seems likely to be true, yet we cannot prove it. Still we find the question interesting in its own right, and in shedding new light on QBB.
The goal now is to show that evaluating 

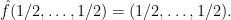
When 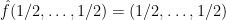

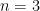


Our approach now is to ask, what happens on arguments 

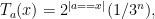
where 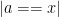


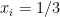



Whenever 



The question is finally whether we can exploit divisibility properties of these related sums of two powers of 
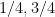
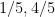
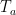
One can also try to imitate the quantum proof further, working with linear extensions of 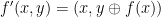


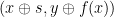

Open Problems
There are two technical open problems. Is the CBB assumption wrong? Can one prove that there is an
Our point is that if the classical-vs.-quantum difference persists with our extension of Simon’s problem, it must reside either in the CBB, or in the problem itself under more powerful conditions. Is this a helpful layering of the issues?
[fixed opening sentence on nature/priority of Simon’s oracle separation][added reference to this discussion][improved exposition of algorithm]
Trackbacks
- No-Go Theorems | Gödel's Lost Letter and P=NP
- My Quantum Debate with Aram Harrow: Timeline, Non-technical Highlights, and Flashbacks I | Combinatorics and more
- Sex, Lies, And Quantum Computers | Gödel's Lost Letter and P=NP
- TOC In The Future | Gödel's Lost Letter and P=NP
- Predictions We Didn’t Make | Gödel's Lost Letter and P=NP
- A Quantum Connection For Matrix Rank | Gödel's Lost Letter and P=NP


We cut from the post a note that there is a recursive structure to Simon’s problem. Given f and s, define f_0(u) = f(0u) and f_1(u) = f(1u). Then f_0 and f_1 map {0,1}^{n-1} to {0,1}^n. If s begins with a 0, then f_0 and f_1 are each still 2-to-1. But if s begins with a 1, then f_0 and f_1 are each 1-to-1. Because: if f_0(u) = f_0(v), then f(0u) = f(0v), but 0u can’t equal s (+) 0v.
We suspect this recursive structure implies by itself that distinguishing B_0 from B_s is classically equivalent to computing s, but we have not yet had time to pursue the mild generalization of Simon’s problem for f: {0,1}^m –> {0,1}^n that this entails.
“And for a companion question, is the QBB assumption really true in prospect? Why is it fair to have a quantum linear operator that can be applied to other quantum states besides the 0-1 basis states, and not be able to do so with a classical multi-linear extension? Or is this where the first power of quantum over classical resides?”
What does “fair” mean here? Classical and quantum are different models of computation. If we can build a quantum computer, even in principle, then the QBB is true. If we can’t build a quantum computer in principle, then you have overturned the most fundamental physical theory known to man.
No, general relativity and quantum theory have not been reconciled, but all attempts to fix this accept quantum theory. At the moment and for the last 100 years there have been no alternatives. Overturning quantum theory would be like overturning probability theory (which is generalized but not overturned by quantum).
First of all, a correction: the honor of the first oracle separation of BQP and BPP belongs to Bernstein and Vazirani. My algorithm merely expanded the separation from superpolynomial to exponential.
Second, like Anonymous above, I’m puzzled by your concern about the QBB assumption. As you point out, “[i]t is justified by polynomial-time universality theorems for quantum circuits”. Moreover, those theorems do not (indeed, cannot) assume that “the matrix computes the function at any algebraic input” in a feasibly constructible way. That’s presumably why, for example, Shor felt obligated to show how his algorithm still worked if all individual operations only operated on inputs and outputs taken from a polynomially bounded number of possible values.
Thanks for the fix and sorry—I see it clearly on page 2 of your paper. Is it also correct to say it’s the first randomized separation?
Interesting about Shor’s motivation, which I regarded as being about precision—not sure if it speaks to the issue we perceive about having an algebraic extension, will ponder further…
I’m not certain that the issue of “precision” is distinct from the issue you raise. (Of course, I’m not certain it isn’t, either…)
Let me rephrase my concern as a question: what is your justification for specifically invoking an *arithmetic* circuit in your CBB assumption, given that its basic components have (at least) exponential-size domains and ranges–unlike the quantum circuits constructed under the QBB assumption, and in standard quantum algorithm constructions? Wouldn’t a quantum circuit construction (say, one attempting to justify the QBB assumption) that used quantum circuits with exponential-sized domains and ranges be dismissed as merely exploiting analog precision, rather than quantum effects?
Oops–please ignore this last comment. Sorry…
The thought behind it is nothing more than the fact that U_f is an operator on C (or C^{2n} in this case), and its actual application in the algorithm is on quantum states that have algebraic entries (over the standard basis).
Per comment elsewhere, I missed that Scott and Avi’s paper already had an oracle sep of BQP^f from BPP^{f-hat}. So we can play up the significance of that—with technical Qs such as Scott proposes below on whether that holds in your case, with an exponential separation. And something I’ve asked privately about cases where obtaining an arith circuit for f-hat might be factoring-equivalent.
Just FYI, Dick and I are QC skeptics and also sign on in varying degrees to the idea that factoring is in [BP]P, so where Scott seems to use the plausibility of factoring being hard to support a conjectured negative answer to what my final section of the post is trying to do (if I understand him correctly?), to us it goes in the other direction as a motivation to try.
I guess I’m still having trouble understanding the motivation for this extension. To me, there’s a perfectly reasonable classical analogy to the quantum world’s unitary operator with arithmetic entries: the classical stochastic operator with arithmetic entries. Now, as it happens, we know that this operator is no more interesting than deterministic computation on a bunch of input bits, some of which are random, whereas quantum operators can’t be reduced to deterministic computation on a bunch of input bits, some of which are in quantum superpositions. But that’s kind of the point, it seems to me–using quantum operators, which involve quantum amplitude rather than classical probability, makes possible some weird effects that don’t appear efficiently simulate-able in the classical world.
So if classical stochastic operators allow for arithmetic entries, then what’s the “intermediate step” between the quantum and classical cases that the extension is supposed to represent?
Where is this SBB assumption made? Quantum circuits may have ancilla/garbage bits that must be initialized to zero. They also carry their input through. Assuming a polytime computable reversible function has a poly-time reversible circuit seems extremely strong, and would imply quantum computers can invert any one-way permutation. I’ve never heard of anyone believing that. Rather,
it is reversible function g(x,y,z), where we know that g(x,0,0) = (x, f(x), 0). We can’t use such a circuit to invert f, because we would need to put “x” into the reversed circuit.
Infact this is really in some sense what one-wayness is saying in a physical sense: it’s possible to easily create information which is then extremely hard to ERASE.
Dick, if you check out pages 27-28 of my and Avi’s algebrization paper, you’ll find an exponential separation between quantum and classical randomized oracle algorithms, even in the case where the classical algorithm can also query a low-degree polynomial extension of the oracle function.
(This follows from Ran Raz’s exponential separation between quantum and classical communication complexity, together with my and Avi’s “transfer principle” from communication complexity separations to algebraic oracle separations.)
It’s an interesting question whether one can prove an exponential lower bound on the classical query complexity of Simon’s problem if the algorithm gets to query a low-degree extension. Let me conjecture right now that the answer was yes. For, if your strange speculation was true, then I don’t see why it wouldn’t also be true for Shor’s period-finding problem (which is just Simon’s problem with a different underlying abelian group). In that case, we would get a polynomial-time classical factoring algorithm.
Thanks—indeed, it’s part (v) on p28—missed it while looking for stuff on hardness of getting the extension in your paper and [IKK09]. That speaks to what we’re thinking about, and we’ll study [Raz 1999] further—we plan to blog more on quantum promise problems anyway. Your last paragraph is getting at our motivation for raising these speculations—note also I fixed the intro by saying Simon’s BQP-classical oracle sep is exponential.
On the problem of getting a multilinear extension, Rahul Santhanam points out privately that this paper by Emmanuele Viola (CCC’03, journal 2004) gives a more-inherent reason why it’s hard: “If one could compute multi-linear extensions efficiently, then since the multi-linear extension is mildly average-case hard, the XOR lemma can be used to get strong average case hardness, which by Viola’s results can’t be done within PH.” He also draws attention to this paper by Juma-Kabanets-Rackoff-Shpilka. Ryan O’Donnell adds that maybe querying interior points of the Boolean cube doesn’t buy anything you can’t already get by sampling its vertices.
It seems to me that building a quantum computer with n qubits should require an exponential (as a function of n) amount of energy to manufacture, because of quantum decoherence.
Since time is proportional to energy in cost, why isn’t this empirical observation not taken into account when analyzing quantum algorithms?
Sorry, I meant “why isn’t this empirical observation taken into account….”
We—maybe I should say I here—don’t believe exponential, but I do believe the “effort” to build and execute the white-box for a given “f” in Simon’s problem—or Grover for that matter—is more like n^2 than n. I have not yet been able to articulate precisely what “effort” means—not energy or entropy per-se but something connecting that with elapsed time. For something precise that our thoughts align with, here is the latest ArXiv version of a paper by Gil Kalai dealing with issues of noise and decoherence as you say.
What mutes our point and made the post hard to write is that QBB strikes us (me) as a quadratic-versus-linear issue, whereas CBB involves exponential. Well Dick and I did both agree on the “tank” vs. “missile” simile, aware that a missile is generally stronger than a tank.
Craig, to the extent that your question is at least partially concerned with the energy cost of initializing the qubits of a quantum computer, you will find it discussed in the QIST Roadmap (LANL/LA-UR-04-1778, “A Quantum Information Science and Technology Roadmap,” 2004) as the second of the five DiVincenzo criteria: “the ability to initialize the state of the qubits to a simple fiducial state” (per page 5 of the PDF file).
Means for achieving this capability are discussed in QIST Section 6.3.0 (per page 29 of the PDF file); these means include creating pseudopure states in liquids, dynamic nuclear polarization (DNP) in solids, and optical nuclear polarization in solids (moreover, the QIST compiler David Cory has himself authored numerous excellent articles on these methods). The short summary is that all quantum computing methods require initialized qubit states of near-zero entropy.
Working over many decades, numerous celebrated physicists (a partial list includes Hertz, Dirac, Feynman, Lawrence, Kapitsa, Landau, Onsager, Townes, Seaborg, Urey, and Mitchell) have evolved an armamentarium of general-purpose methods for entropy-reduction that are simultaneously informatically elegant, physically ingenious, and eminently practical. Generically these methods do not require the expenditure of infinite or near-infinite energy (`cuz otherwise, they wouldn’t be practical). Moreover in recent year’s the QIST program itself has contributed greatly to humanity’s still-accelerating practical capabilities in this area.
The overall theme of the present Gödel’s Lost Letter is rather more exploratory. I am reading the discussion intently (without claiming a full appreciation of it) because it so enjoyably calls to mind the credo of the 18th century playwright and dramaturg Gotthold Lessing (as quoted by Hannah Arendt in a celebrated essay On Humanity in Dark Times: Thoughts on Lessing):
Long live Gödel’s Lost Letter as complexity theory’s foremost and much-appreciated source — in these dark times — of mathematical, scientific, and technological fermenta cognitionis!
Craig, the reason that “empirical observation” isn’t taken into account is that it was studied in great detail in the mid-90s and discovered to be false, at least assuming that quantum mechanics itself remains valid. Once you push the decoherence rate per qubit down to some finite nonzero level, you can use quantum error-correction to do an n-qubit quantum computation using time and energy that scale only polynomially with n (indeed with quite small overheads), not exponentially. Google the Threshold Theorem. Hope that answers your question.
My empirical observation is based on the fact that the largest quantum computer that I’ve heard of is claimed to use 128 qubits by D-Wave and that’s debated. http://news.sciencemag.org/sciencenow/2011/05/controversial-computer-is-at-lea.html
I think quantum computers are a lot like folding paper in half. Fold paper in half once, no problem, fold it in half twice, no problem, …., fold it in half 13 times, big problem.
The traditional interpretation of quantum mechanics must be wrong, because it’s too ridiculous to be correct. It’s good that people are trying to build quantum computers, so they’ll find this out.
People could have told Charles Babbage in the 1830s that his proposal would obviously never scale to a large number of classical bits. The evidence for that “empirical observation”? Well, it hasn’t scaled yet, has it? 🙂
So, if we want to discuss this at something above a Fox News level, it better be on the basis of our physical theories and what they tell us about how the world works.
Quantum mechanics has survived every single experimental test without exception since the 1920s, including tests like Bell inequality violation that skeptics were sure it wouldn’t pass. If quantum mechanics is wrong (and note that for quantum computing to be impossible, the theory itself, not just some “traditional interpretation” of it, would need to fail!), that will be the most astounding discovery in physics for almost a century. Certainly it will be orders of magnitude more exciting than “merely” building a scalable quantum computer, and will be scientifically the best outcome imaginable from quantum computing research. I’m not such a wild-eyed optimist; that’s why my “default prediction” is that building a QC will indeed be possible. 🙂
As an amateur magician, I see the experiments which are used to justify quantum mechanics, my favorite being the experiment described in Feynman’s Lectures in Physics the double slit experiment, as like watching a magic show. There are two ways to watch a magic show: (1) You believe everything you see. (2) You try to figure it out.
It seems to me that scientists today observe nature like (1). I prefer to observe nature like (2). If you observe nature like (1), you end up with the present interpretation of quantum mechanics. If you observe nature like (2), you end up with a classical interpretation of the double slit experiment.
There are books which offer a classical interpretation of the double slit experiment by Carver Mead and Milo Wolff, which assume that everything is waves and their resonance and there are no quantum jumps (the observed quantum jumps are the result of nonlinearities in the equations). This is why I don’t believe the present interpretation of quantum mechanics phenomena. Because it’s like believing everything you see in a magic show.
I would ask how you explain, say, Bell inequality violations without “the present interpretation of quantum mechanics” (by which you actually mean: “quantum mechanics”), but on second thought, I’m not even sure I want to know the answer…
Why don’t you want to know the answer? Is it kind of like “I don’t even want to know how the magician did it, because that would spoil the magic?”
If so, then I don’t want to spoil the magic, so I won’t give the answer.
No, because I’m pretty sure I’ve heard every possible answer as to “how the magician violated the Bell inequality” over the past decade, and without exception, the answers have been not just wrong but aggressively wrong—basically amounting to foot-stomping redefinitions of words like “local.”
Scott,
You’re almost as closeminded as I am.
Craig,
I love your paper sheet analogy, though I was never able to fold one any further than seven times. 🙂
The possibility of doing cryptography seems to be a law of nature: any two thinking subjects can always communicate secretly with each other. Therefore, the ability for quantum computers to break cipher codes looks like a good reason for me to doubt their feasibility.
Serge,
I didn’t use the number 13 for no reason: See http://pomonahistorical.org/12times.htm and http://en.wikipedia.org/wiki/Mathematics_of_paper_folding
As for more alternative explanations for quantum mechanics see http://youstupidrelativist.com/ (I don’t agree with everything he says nor do I agree with his tactic of ridiculing his opponents to get his point across, but some of it is interesting or at least entertaining. He has a whole series on youtube.) I think he sees things like I see things, that physics should make sense intuitively, unlike physics in its present state.
Serge, quick point of information. Even if (for whatever reasons) you adopt as an axiom that there should exist cryptographic codes that are hard to break—and declare that the universe itself has to respect your axiom—that still doesn’t give you a reason to reject quantum computing. Today we have classical public-key encryption schemes, other than RSA, which as far as anyone knows are secure even against quantum computers. (An excellent example is lattice-based encryption — see for example the schemes of Ajtai-Dwork and Regev.)
Furthermore, if you don’t require short encryption keys or a public encryption procedure, then there’s always the good old one-time pad, which (if used correctly) is secure not only against quantum computers, but any computer that could ever be invented. Finally, if you don’t like the one-time pad, then quantum mechanics even enables an entirely new type of encryption, namely BB84 quantum key distribution (which, unlike quantum computing, is already practical today).
And Craig, let’s all strive to be as open-minded as we possibly can, in every situation where the evidence is not yet known. And even for cases like quantum mechanics—where the evidence was massively in and a clear verdict rendered already by the late 1920s, and where that verdict has only been reconfirmed over and over since then—let’s all be willing and even eager to reopen the case, if interesting new arguments or evidence emerge to force the case open.
But when someone with even a smidgen of knowledge visits youstupidrelativist.com (or one of the countless similar sites), do you think they see interesting new arguments or evidence to force the case open? Or, once they click past the mouse-cartoons of Newton, Einstein, and Hawking, do you think they see stupendous ignorance of the old arguments and evidence in almost every sentence—in short, someone who simply doesn’t know the case file? Think carefully about the answer!
Scott,
I don’t agree that being open-minded is always good.
For instance, I’m closeminded in that if I see something that I can’t figure it out (like say David Copperfield vanishing the Statue of Liberty), I don’t believe that he did magic. I assume that he did so by some natural means, but I don’t know what the natural means is. If I were open-minded, I would have to conclude that David Copperfield really did make the Statue of Liberty dissapear. (BTW, I do know how he did it; he used Romulan cloaking technology from Star Trek.)
Similar with quantum mechanics. I’m closeminded in that I don’t believe it in it’s present interpretation even though I’ll confess that the answers I’ve heard to the “how the magician violated the Bell inequality” are kind of forced.
As for youstupidrelativist.com, it’s just entertainment, sort of like Rush Limbaugh arguing scientific conservatism instead of political conservatism. But I doubt he could become rich by having a radio show about how the liberals have taken over science, because most people don’t really care.
Craig, I think your analogy between quantum mechanics and stage magic fails for the following reason.
A magician constantly tries to confound his audience: as soon as there’s any danger of people figuring out the trick, or even just getting too familiar with it, he switches to a different trick, thereby maintaining the atmosphere of confusion, wonder, delight, etc.
With quantum mechanics, by contrast, there’s been only one trick since the 1920s: namely, the replacement of probabilities by complex-valued amplitudes. And once you understand that trick (or even just provisionally accept that Nature does it), everything else about the behavior of the subatomic world becomes immediately explicable in terms of it. Just like with any other phenomenon, one can and should ask “OK, but how and why does Nature do that? Is there some deeper underlying explanation?”
But even without such an explanation, when the same “magic trick” gets repeated over and over for a century, so reliably that every laser and semiconductor (and even our understanding of matter itself) is based on it, using precisely the same mathematical formalism, at some point it’s not just a magic trick: it’s physics!
Scott, thank you for the quick point. I was too quick myself at forgetting that cipher codes can be based on harder problems than integer factorization. Now I’m ready to accept the idea of large-scale quantum computers – provided nonetheless that the universe will still respect my axiom. This sounds like a win-win agreement, doesn’t it? 😉
This observation is incorrect. It is known that local decoherence only imposes a poly-logarithmic overhead—not even polynomial! The exact exponent on the logarithm is unknown, but it is at most 3.
This should not be surprising (in hindsight!). Similar statements, with similar overheads, are known for classical fault-tolerant computation, and nearly the same techniques work quantumly.
Anonymous—not sure if you mean “this observation” as mine (doubting the t*log(t) fault-tolerance overhead up to quadratic) or Craig’s. Scott too and everyone else who has cited the threshold theorem, what do you think of Gil Kalai’s paper which I’ve linked in my comment just above? It is not clear (to me) how his doubt might translate quantitatively into a different overhead from O(t [poly-]log t).
You can find a t * poly(log t) statement in Theorem 6 of Aliferis/Gottesman/Preskill, arXiv:quant-ph/0504218, for example. Have you found an error in their proof?
Kalai’s paper is not exactly right.
1. Consider his conjectures 2 and 3 on the errors affecting a quantum computer. A quantum computer is a physical system, but he gives no physical reason for these conjectures to hold. Instead, he shows a picture of metronomes. It seems like a joke.
2. Kalai admits himself that if his conjectures are true, then it is possible to signal faster than the speed of light. Most physicists would see this as a problem.
3. All of Kalai’s objections to quantum computers apply also to classical computers. He might be correct, and a truly large-scale classical computer cannot be built, but in practice large enough computers can be built.
Hmm, I have just learned about this discussion. Regarding anonymous’s points. It seems that he did not read the paper carefully.
Point 2 is simply incorrect. Of course, there is nothing in my conjectures which suggest that you can signal faster than the speed of light.
Point 3 and the distinction between classical and quantum error correction is a serious issue which is discussed in the paper. It is not an issue that only quantum computer skeptics should worry about. After all, classical error correction is massively witnessed in nature while quantum error correction isnt (to the best of our knowledge, so far)
The main purpose of the conjectures is to descibe formally what it means for a physical system “not to demonstrate quantum error correction”. In other words, what is the formal distinction between quantum systems that do not demonstrate quantum fault tolerance (which include everything we witness so far) and quantum systems that demonstrate fault tolerance. Anonymous is correct in saying that I do not exhibit a definite common physical reason why these conjectures will hold. The reason is simple, there are various different reasons depending on specific architecture and implementation. The more hypothetical a proposed suggestion for quantum computer is the more difficult it is to describe precisely what will cause my conjecture to hold. However, I think it will be easier to see why my conjectures hold for concrete suggestions such as topological quantum computing (using anyons) and measurement-based quantum computing (using cluster states).
Craig, one way to upgrade this discussion is to point to references that respect the (highly enjoyable) iconoclasm of sites like “YouStupidRelativist.Com”, but offer better mathematical foundations.
If we restrict our attention to undergraduate texts, a suggested three-step program is first to ask oneself “Do I understand classical mechanics?” before-and-after reading Saunders Mac Lane’s 1970 Chauvenet Lecture Hamiltonian mechanics and geometry. Suggested followup reading includes Vladimir Arnol’d’s Mathematical Methods of Classical Mechanics (1978) and Michael Spivak’s Physics for Mathematicians (2010), and this will prepare you to read-and-understand practical engineering texts like Daan Frenkel and and Berend Smit’s Understanding Molecular Simulation: from Algorithms to Applications (1996), see in particular the discussions relating to thermodynamic ensembles, phase transitions, and symplectic integration; these topics of course have considerable practical importance.
A natural second step is to ask oneself “Do I understand quantum mechanics?” before-and-after reading Abhay Ashtekar and Troy Schilling’s Geometrical formulation of quantum mechanics (1997, arXiv:gr-qc/9706069). A practical test is to systematically translateMichael Nielsen and Isaac Chuang’s Quantum Computation and Quantum Information into the geometric language of Ashtekar and Schilling, in particular reproducing in the quantum domain the classical results of Frenkel and Smit. At this stage mighty few physical systems will intimidate the reader, who will be prepared and motivated to tackle the burgeoning systems engineering literature of chemistry, optics, condensed matter physics, and synthetic biology, and moreover will be equipped also to read the literature on the foundations of classical quantum mechanics with fresh enthusiasm (here Colin McLarty’s writings are especially recommended).
A natural third step is to ask oneself “Do I understand classical and quantum information theory?”before-and-after reading (what else?) Gödel’s Lost Letter and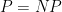 . Because Dick Lipton and Ken Regan do a terrific job on this forum of serving us fine wine in fresh skins — in particular fine complexity-theoretic wine in fresh geometric skins — very much in the honorable and wonderfully successful mathematical tradition of researchers like Mac Lane, Arnol’d, Spivak, Ashtekar, and Schilling. And for this ongoing service Dick and Ken deserve everyone’s appreciation and thanks.
. Because Dick Lipton and Ken Regan do a terrific job on this forum of serving us fine wine in fresh skins — in particular fine complexity-theoretic wine in fresh geometric skins — very much in the honorable and wonderfully successful mathematical tradition of researchers like Mac Lane, Arnol’d, Spivak, Ashtekar, and Schilling. And for this ongoing service Dick and Ken deserve everyone’s appreciation and thanks.
In summary, Scott Aaronson (in his comments on this thread) is of course entirely correct in reminding us that:
With varying degrees of optimism, many people (including me) share Scott’s hope that this dystopian state-of-affairs will not persist much longer! We can all hopefully foresee that by the end of the 21st century — in consequence of the many mathematical innovations that are transforming our understanding of dynamics, simulation, and information — our present notions of Hilbert space, the superposition principle, and information-theoretic oracles will be regarded with the same nostalgic fondness that we presently have for quaint notions like phlogiston, the æther, and Newtonian dynamics. 🙂
John,
I don’t know if I’ve said it before, but this website is really an awesome resource for computer science. I cannot figure out how Dick Lipton and Ken Regan have been able to be so consistent in putting up such interesting posts in such a short period of time. That takes a heck of a lot of talent.
Simon’s comment about the limitations of quantum algorithms misses the elephant in the room that started the whole field: quantum computers can efficiently simulate quantum systems. Here’s a recent example that accounts for a large fraction of all current supercomputer time.
About Kalai’s paper, it suffers the same flaw as many other critiques of quantum fault-tolerance: if true, its arguments would apply equally well to classical computing. (He says otherwise, but I don’t understand why he says this. Classical codes are quantum codes that have distance 1 against Z errors.)
As for his specific conjectures, I don’t see much to support them. Conjecture 1 seems to me specifically falsified by the incredibly detailed protocols that people have described for fault-tolerant ancilla preparation. These procedures work, if you believe the error models they assume. Conjectures 2 and 3 seem to confuse entangled states with entangling dynamics. QM is linear, so if the state of the system is entangled, that doesn’t make the noise affecting them any more correlated. (Indeed, it is easy to see that there is no generic test for entanglement, although it is possible to test whether we have one particular entangled state or not.) Perhaps this conjecture would apply if the environment exhibited entanglement that was maliciously correlated with the calculation. However, this sort of correlation is also manageable, given plausible assumptions. As for conjecture 4, I didn’t see why it would falsify FTQC, but maybe I’m missing something.
I’m sorry this explanation is somewhat incomplete. Kalai’s papers deserve a more detailed reply. But for the purpose of this discussion, I wanted to weigh in. Many people look at those papers superficially and conclude that FTQC is in doubt. But I would ask that you understand in detail the specific objections and the replies to them before concluding this.
On a related note, much of the effort in FTQC has been to improve the threshold, or prove the result using weaker assumptions, such as nearest-neighbor gates, or mildly correlated noise. But perhaps a worthwhile project would be to find a really simple proof, perhaps with terrible constants, that could reassure skeptics, and be used for teaching.
Aram, relating to your starting reference to Jordan, Lee, and Preskill’s Quantum algorithms for quantum field theory (arXiv:1111.3633) is there any substantial reason to expect that the scattering amplitudes theory in particular, or the Standard Model in general, are not simulatible with computational resources in
theory in particular, or the Standard Model in general, are not simulatible with computational resources in  ?
?
ArXiv:1111.3633 itself provides neither references nor any argument relating to this postulate, and in light of sustained decades of progress in perturbative field theory, lattice field theory, and (especially) condensed matter physics and quantum chemistry, it’s becoming steadily harder to point to physically measured scattering processes whose scattering amplitudes cannot be computed with classical resources.
This goal in raising this point is not to detract from the Jordan, Lee, and Preskill preprint (which is terrific), but rather to inquire about the broader discipline of simulation physics.
The year 2012 will be the 30-year anniversary of Feynman’s seminal 1982 article Simulating physics with computers. What have we learned in these three decades about the class of dynamical systems that (in Feynman’s words and with Feynman’s emphasis) “cannot be simulated with a normal computer”?
Conversely, we now appreciate that the class of physically feasible experiments that are simulatible-in- is considerably larger than Feynman’s generation thought it was; the increase being due to improvements in both computing hardware and simulation algorithms. A key question for the 21st century simulationists is, what are the fundamental limits to continued improvements?
is considerably larger than Feynman’s generation thought it was; the increase being due to improvements in both computing hardware and simulation algorithms. A key question for the 21st century simulationists is, what are the fundamental limits to continued improvements?
Hi John,
These are good questions. Really this recent paper is just one example of a quantum simulation; as far as I can tell, its key technical contributions are to deal with the unboundedly-large energies and unboundedly-small distances that can arise in quantum field theories. As for being an exponential speedup, this is only relative to the best known classical algorithms; certainly there could be better ones out there, and for all we know, L=PP, and we can calculate acceptance probabilities of quantum computers to exponential accuracy in log space.
But here is the pretty strong evidence so far that quantum systems can’t be simulated in polynomial time.
1. People have tried really hard (e.g. most people doing high-energy particle physics, and condensed matter) and have only made progress in special cases, which we understand to be non-universal.
2. If factoring is hard classically, then quantum simulation must also be.
3. There are oracle separations, which don’t seem totally contrived.
It’s kind of like the evidence that P isn’t equal to NP.
Especially during election years, citizens of democracies suffer through public ceremonies of slogan-shouting, cherry-picking, and witch-hunting known as “debates.” In fortunate contrast, debates among mathematicians, scientists, and engineers are based solely upon rational analysis and objective criteria that leads to a consensus that is reasoned yet provisional and dynamically-evolving.
Uhhhh … right? 🙂
With regard to some of the issues being discussed here on Gödel’s Lost Letter, there is a reasonably well-defined consensus, which this post will now (attempt to) summarize.
First, physical processes of computation — whether classical, quantum, or hybridized — preferably are robust with respect to errors. For classical binary computation (computer processors and memories) systematic error probabilities commonly are below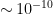 , random errors are below
, random errors are below  , and moreover these errors originate in a relatively small number of physical mechanisms that are well-understood and are bitwise-independent to an excellent approximation. When combined with effective error-correcting codes these favorable attributes yield system-level accuracy and scalability that are as near-perfect as mortal humanity requires, combined with exponentially improving speed, size, and energy-efficiency.
, and moreover these errors originate in a relatively small number of physical mechanisms that are well-understood and are bitwise-independent to an excellent approximation. When combined with effective error-correcting codes these favorable attributes yield system-level accuracy and scalability that are as near-perfect as mortal humanity requires, combined with exponentially improving speed, size, and energy-efficiency.
In the late 1990s there arose the hope — and even the concrete expectation — that quantum computation would follow a similarly progressive trajectory, as was set forth in a considerable body of articles, patents, and roadmaps (see for example Peter Shor’s 1998 patent “Method for reducing decoherence in quantum computer memory,” US5768297 and the 2002 LANL/QIST “Quantum Information Science and Technology Roadmap,” LA-UR-04-1778). However, it’s now apparent that progress toward practical quantum computing has been far slower than was foreseen in the 1990s, for multiple reasons that include generically higher systematic and random error rates, more numerous error mechanisms that are not generically bitwise-independent, and higher computational overhead associated to error correction. In essence it has turned out that noise is the ubiquitous enemy of quantum computing and ally of classical computing; thus for the foreseeable future — which means barring unanticipated dramatic breakthroughs — there’s an emerging consensus (or is there?) that progress toward practical quantum computing is likely to continue to be relatively slow.
It’s worth recognizing, though, that at least some of the seeds that the quantum computing community helped plant and cultivate in the 1990s are sprouting and growing with unanticipated vigor, and even show good promise of blossoming into transformational practical applications; the burgeoning mathematical and informatic ecosystem of Igor Carron’s on-line Matrix Factorization Jungle provides (to my mind) multiple examples of this luxuriant growth. If as Scott Aaronson (and many other researchers) conservatively remind us “quantum mechanics has survived every single experimental test without exception” then nonetheless both the history of science and multiple lines of physical and mathematical reasoning suggest that this simple unqualified truth is unlikely to survive the 21st century. To find out, we’ll have to explore unfamiliar mathematical habitats like the Factorization Jungle, whose remarkable inhabitants no doubt have much to teach us. The glimpsed “Quantum Chocolate Boxes” that are the topic of this particular (wonderfully interesting!) Gödel’s Lost Letter — and perhaps Gil Kalai’s still-more-elusive mathematical Mokèlé-mbèmbé too — are among the remarkable denizens of this still-unexplored 21st century math/science/engineering wilderness … and for this glimpse of unknown mathematical wonders, coupled with the implicit hopeful promise of transformational resources for a planet that sorely requires them, appreciation and thanks are extended as usual.
There’s a simple reason classical computers get low error rates. Every transistor is performing an encoded operation on data protected by an error correcting code. The code is the 1-to-mn repetition code, where n is the # of electrons used per transistor (maybe a million or so? I’m not really sure), and 2^m is the # of energy levels separating the low voltage from the high voltage, which I’m also not exactly sure about. But underlying it all is the same principle as what FTQC is trying to do. It’s just way way easier classically because you get a bigger repetition code simply by making the wire bigger.
Aram, to affirm your answers, a one-volt potential applied to a gate capacitor of area and thickness
and thickness 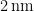 corresponds to a charge of order 50 electrons and energy of order
corresponds to a charge of order 50 electrons and energy of order  ; thus the chance of a thermal fluctuation accidentally switching any given classical gate is negligible (not so for cosmic rays however).
; thus the chance of a thermal fluctuation accidentally switching any given classical gate is negligible (not so for cosmic rays however).
But a striking point underlies Craig’s posts too (as I understand them), namely that one full century following the inception of quantum mechanics, there is still no set of observational, experimental, or computational data we can point to and say “This data set provably cannot be simulated with resources in .”
.”
Or more concretely: “With resources in we can simulate a data set that will pass any validation test — including tests entailing comparisons with data from replicated experiments — that a real data set can pass.”
we can simulate a data set that will pass any validation test — including tests entailing comparisons with data from replicated experiments — that a real data set can pass.”
In this sense algorithms in are proving to be strikingly powerful in explaining the real (quantum) world, and the fundamental limits to their power are by no means fully established. That was the serious point behind my tongue-in-cheek answer to the Fortnow/GASARCH PvsNP poll.
are proving to be strikingly powerful in explaining the real (quantum) world, and the fundamental limits to their power are by no means fully established. That was the serious point behind my tongue-in-cheek answer to the Fortnow/GASARCH PvsNP poll.
We can’t show BQP is outside of P not because we lack experimental data, but because lower bounds in complexity theory are hard.
Not only are lower bounds hard, but they’re most of the time impossible. Whenever you find it difficult to write a fast algorithm for some problem, you’re inclined to believe that it’s hard. But which problem is: the original one, or finding a fast algorithm? This is utterly impossible to decide.
They say that if P was equal to NP then mathematical creativity could be automatized. But it already is! Isn’t the brain a computer? The impossible task is not for a computer to be creative. It is, for any processor, to write out the rules of its own creativity.
There is a problem with the statement “quantum mechanics has survived every single experimental test without exception” with respect to quantum computing. The issue is not whether quantum mechanics is correct or not. The issue is whether you can even design the experimental tests for quantum computing to begin with.
It’s sort of like the statement by Homer Simpson, “Marge, I agree with you — in theory. In theory, communism works. In theory.” The same thing with quantum computers: “Quantum computerologists, I agree with you — in theory. In theory, quantum computing works. In theory.”
Craig, people believe quantum mechanics because after trying really hard to get alternate theories to work, this is the only one we have found that explains all of the data, and works consistently (apart from the difficulties with general relativity).
Contrary to what it might seem, there has been resistance from the beginning to wave-particle duality, entanglement, uncertainty, etc. We accept them not because we are trusting folks, but because the overwhelming mass of evidence has forced us to.
That being said, a single experimental refutation of any aspect of quantum mechanics would be a quick route to a Nobel prize, so if you have ideas, please let us know! (Or try them yourself.)
Aram,
I believe in quantum mechanics in that it predicts the result of experiments that have been done.
However, I don’t think quantum mechanics predicts that large-scale quantum computing will work. It only predicts that large-scale quantum computing will work if you can build a large-scale quantum computer. But it doesn’t predict that you can build a large-scale quantum computer.
My opinions have been confirmed, as John Sidles said above, “… there’s an emerging consensus (or is there?) that progress toward practical quantum computing is likely to continue to be relatively slow.”
I would propose a modified Moore’s law for quantum computers, that exp(the number of qubits) doubles every x years.
Sure, it’s a difficult engineering challenge. It may prove too difficult, or more likely, not worth the cost.
But that’s different from Kalai-style objections which posit some fundamental feature about noise that would prevent QC even in principle.
What John says is true, depending on your definition of “relatively slow.” Yes, slow relative to early hype. But there’s rapid progress in reducing noise rates in a variety of different systems. Even “exponential” progress, if you want to try to fit Moore’s-Law-type curves.
For noise rates, they are still tracking an exponential. Taken from http://intractability.princeton.edu/blog/2011/09/princeton-quantum-computing-day/
Matthias Steffen (manager, Experimental Quantum Computing)
Title: IBM’s Efforts Towards Building a Quantum Computer
Abstract: Coherence times for superconducting qubits (in 2D) have
increased drastically over the past 10 years with improvements
exceeding a factor of 1000x. However, with a few exceptions, these
appeared to have reached a plateau around 1-2 microseconds, the
limits of which were not well understood. Here, we present
experimental data showing that one limit is due to infra-red
radiation, confirming observations from other groups. With
appropriate IR shielding, we observe coherence times (T1 and T2) near
5 microseconds. …
Just to be clear, it seems to me that documents like the 2002-4 QIST Roadmaps are very far from “hype,” but rather rank among the most serious, carefully considered, and scientifically valuable documents yet written … provided that we appreciate these roadmaps broadly as directing us toward new knowledge and capabilities, rather than narrowly as time-lines for product development. Moreover, striking new capabilities are emerging from this knowledge, albeit not always in the forms originally anticipated, and is the natural and hoped-for outcome of such enterprises.
I just want to revive the comment by “gradstudent”, who wrote:
Where is this [QBB] assumption made? Quantum circuits may have ancilla/garbage bits that must be initialized to zero. They also carry their input through. Assuming a polytime computable reversible function has a poly-time reversible circuit seems extremely strong, and would imply quantum computers can invert any one-way permutation. I’ve never heard of anyone believing that. Rather,
it is reversible function g(x,y,z), where we know that g(x,0,0) = (x, f(x), 0). We can’t use such a circuit to invert f, because we would need to put “x” into the reversed circuit.
In fact this is really in some sense what one-wayness is saying in a physical sense: it’s possible to easily create information which is then extremely hard to ERASE.
The way I read the QBB assumption, gradstudent is right. The version of the QBB that is true in the standard quantum complexity model is that one can convert any *reversible* classical circuit (one in which *every gate* is a permutation) to a quantum circuit whose corresponding unitary matrix is a permutation matrix (in the computational basis). The issue is that there are a number of permutations which we know how to compute but for which we don’t know efficient reversible circuits. In particular, any one-way permutation (since a reversible circuit would be easy to, um, reverse). The distinction is a bit like the one for monotone versus nonmonotone gates. There are monotone functions which have small nonmonotone circuits but which provably require large *monotone* circuits.
Ken and Dick, was your QBB stated intentionally to grant quantum computers the power to invert one-way permutations?
Adam, that might seem like an important issue, but the model actually finesses it as follows: when we talk about computing a function y = f(x) in the quantum setting, we actually mean that we compute the pair (x, y xor 0) from the pair (x,0)–that is, the final state always includes the initial state, and the function value is actually xor’ed with the extra zeroes. This is actually necessary, because quantum computations can never destroy state, in any sense–every operation, even at the bit level, must be completely reversible.
Thus there are no “one-way” permutations, in the usual sense: to compute a one-way permutation f, we compute the value (x, f(x) xor 0) from (x, 0)–and we can in fact reverse this computation simply by performing it again.
Simon’s algorithm doesn’t rely on f being something we know how to invert; indeed ,it doesn’t have to be invertible. It uses the standard oracle model in which we can map |x>|y> to |x>|y \oplus f(x)>.
This in turn can be achieved using any non-reversible circuit for f. First we turn this into a reversible circuit that maps |x>|0>|0> to |x>|f(x)>|g(x)>, then we CNOT the answer onto |y> and uncompute.
Dan and Aram,
I understand the way that circuits are normally made reversible. The issue is that the current statement of QBB is (as I see it) misleading:
“Given an invertible function, there is a unitary matrix that implements the function as a permutation matrix, and moreover: the matrix is efficiently constructible, in a way that is realizable by a physical system.”
The issues are that
a) the original function need not be invertible and
b) there is a unitary matrix that implements a related function (which is invertible), for which we have a related circuit.
-adam
Adam: Sorry, yeah, you’re right. I misread your point.
Note that the QBB assumption is almost certainly false as the original post stated it. (First, let’s modify it to say “Given an invertible function for which there exists an efficient classical algorithm“.)
If that assumption held, then quantum computers would be able to break any one-way permutation. Why? Because if a quantum computer can implement a controlled-U operation, then it can also apply U-1. See arXiv:0810.3843 or arXiv:0811.3171.
Aah, I see…I’d noticed that, but just assumed it was a typo or something–as far as I know, the function itself has to be efficiently computable as well as invertible. Otherwise, BQP would be a lot more powerful than we currently believe it to be…
(I don’t think there’s anything in the rest of Ken’s post that contradicts my assumption about what he meant, but perhaps I’m mistaken…)
We did mean “efficient(ly)” to be implicit in the statement of the QBB—we didn’t specify “polynomial” or “[BP]P” because our (my) actual belief is that there is a roughly linear-vs.-quadratic issue. I think we both thought that saying “invertible” took care of the one-way-permutation issue—I know that as part of my last-minute editing pass, I considered hard-wiring the “(x,y)|–>(x,y(+)f(x))” form in or right after the QBB statement, but wanted to leave the intro as prose and figured it was there in the technical parts.
To answer Dan above querying whether an algebraic (or specifically multi-linear) extension rather than a probabilistic operator serves as a “fair” analogue, the main thing is that at various points in the past 3 weeks I’ve thought I had solved the combinatorial problems in the last section, or was close to doing so…otherwise this was supposed to come right after the first “quantum chocolate” post. The upshot to me is that there’s a lot more combinatorics underlying the “Algebrization” papers than I had realized.
Thanks to everyone for a lot of interesting comments! Regarding Gil Kalai’s paper (here again is the June 2011 version and Jan 2011 slides) and point 2 of this objection above, the objector is mis-attributing Kalai himself, but may be thinking of this paper by Ulvi Yurtsever, which shows (IIUC) that any prediction advantage against quantum coinflips implies super-c communication.
A few remarks about my papers. 1) Let me mention a slightly updated version of my paper mentioned above (following some correspondence with Aram some time ago): http://www.ma.huji.ac.il/~kalai/Qitamar.pdf . Also an earlier closely related paper “when noise accumulates” ( http://gilkalai.files.wordpress.com/2009/12/qi.pdf ) has it last section dealing with some critique similar to some expressed here.
2) Perhaps the easiest conjecture (Conjecture 1) to formulate is this one:
In every implementation of quantum error correcting code with one encoded qubit, the probability of not getting the intended qubit is at least some δ>0, independently of the number of qubits used for encoding.
Another way to say it is this. Consider a single encoded qubit described by n qubits. Quantum fault tolerance enables you to have the state of this encoded qubit closer and closer to a delta function (concentrated on the desired encoded qubit) as n grows. My conjecture is that no matter how large n is, when you implement quantum error correction to encode a single qubit the state of the encoded qubit will be a substantial mixture with unintended states.
When you consider classical error correcting codes as quantum codes, in the way Aram suggested my conjecture holds automatically. The encoded state, regarded as a single qubit state, is, to start with, a substantial mixture.
So my paper is rather careful to describe the conjectures in a way which has no consequences for classical error correction.
3) I completely agree with Aram when he says “Conjecture 1 seems to me specifically falsified by the incredibly detailed protocols that people have described for fault-tolerant ancilla preparation. These procedures work, if you believe the error models they assume.”
Sure, this is the point. Believing Conjecture 1 requires not believing the error-models assumed in the theory of FTQC, (and vice versa) and even not the “plausible” error models in Aharonov-Kitaev-Preskill’s paper cited above.
Maybe it is too late in the thread (and too late here in Tel Aviv) to discuss my other conjectures that Aram referred to and the many interesting other issues. A really interesting question raised here (again) is: “If quantum fault tolerance is impossible” what does it says about physics, or a slight variation ” How quantum physics looks without quantum fault tolerance”.
Gil Kalai asks:
Gil’s fine question is indeed cousin to the question that Dick and Ken asked:
In the classical domain Gil’s question is cognate to:
To which 18th century navigators and surveyors gave a well-framed answer:
By the end of the 18th century even common sailors had achieved a working computational appreciation of this problem — an appreciation that was both eminently practical yet mathematically natural — yet many decades were to pass before 19th century mathematicians like Gauss and Riemann succeeded in formalizing the sailors’ working computational methods.
Similarly, nowadays mathematicians, scientists, and engineers alike have achieved a working computational appreciation of the well-validated 20th century intuition that
Obviously neither Dick nor Ken nor Gil — nor anyone else — has yet formalized this working 20th century intuition in a form that is sufficiently beautiful and natural to qualify as a 21st century axiom and/or physical law. In this respect history counsels patience and persistence.
Fortunately, pretty much everyone posting on this thread is in non-Bœotian accord that this is a wonder-filled quest, in which junior and senior researchers alike have outstanding prospects for creative mathematical and scientific discovery, and even good practical prospects for creating the transformational new capabilities and resources that our planet so sorely requires. Exactly as Scott Aaronson posted, such an outcome would be
A celebrated 19th century sea-captain expressed this same sentiment as follows:
Now, supposing that it were the case that the classical-quantum wall were single-layered, tissue-thin, and easily thrust-through … well … would that really be a desirable state of affairs? Because battling the tough obstructions to our quests generally leaves us better-off. As that same 19th century sea-captain put it:
That’s why Gil’s question is a good question. 🙂