Quantum Algorithms A Different View
Quantum algorithms explained in a different way, not the usual way.

David Deutsch is one of the founders of quantum computing. His 1985 paper described quantum Turing machines, and his famous algorithm is considered the first quantum algorithm ever.
Today I plan to try to explain the power of quantum algorithms, but do it in my way. I hope this “explanation” will help you understand their power, yet avoid some of the complexities with the usual explanations.
There is something “magical” about quantum algorithms. This magic can make one, like me, who is not an expert in quantum mechanics feel lost. I have even published a paper on this subject years ago—it was a generalization of Peter Shor’s famous factorization algorithm. And it is joint work with Dan Boneh, which I will discuss another time.
Yet I still feel puzzled. I guess being puzzled seems to be the first step toward showing that you “understand” quantum algorithms (QA). Here are three quotes from two famous physicists and one famous non-physicist on quantum mechanics.
- Niels Bohr:
If quantum mechanics hasn’t profoundly shocked you, you haven’t understood it yet.
- Richard Feynman:
I think I can safely say that nobody understands quantum mechanics.
- Groucho Marx:
Very interesting theory—it makes no sense at all.
If you think you understand, then you do not—a very strange state of affairs. Let’s turn to QA’s and in particular Deutsch’s famous algorithm.
Trying To Teach Quantum Algorithms
This last spring I taught a class at Tech on computational complexity. At the end of the semester I decided to present some basic ideas from quantum computation (QA). I thought the best way to introduce the class to the power of QA was to present the famous “simple” algorithm 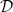
I thought wrong. I looked on the web—where else—and found many detailed descriptions of how Deutsch’s algorithm works. These descriptions are detailed, use special notation, and give no intuition on why the algorithm works. At least for me the descriptions were not very insightful.
I did present the algorithm to my class, and used lots of extra comments to try to help them understand what was going on. I was not happy with the outcome. I think part of the class got something out of the lecture, yet I felt that most were probably not really following. In my experience if I do not understand something, it is pretty hard to explain to others.
This failure led me to think about how to explain this famous algorithm. I have some ideas of how to do this that I would like to share with you. I hope the following has two properties: one that it helps you understand QA’s better than before, and that my expert friends will not find it incorrect or worse silly.
Deutsch’s Problem
Suppose Alice and Bob decide to play a simple “game.” Bob selects a boolean function 
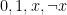


In the classical world Alice simply asks Bob for the values of 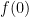
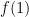

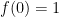
Deutsch’s brilliant insight is that the quantum world is different. Alice can determine whether Bob has selected a constant function or not in one evaluation. She can do this with quantum magic.
Quantum Basics
In order to explain Deutsch’s Algorithm (

![\displaystyle [a,b]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where each 
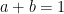



Every step of a probabilistic computation must preserve that the total state is a distribution. This implies that each step of the computation must be described by some stochastic matrix 
![\displaystyle \left[ {\begin{array}{cc} p_1 & q_1 \\ p_2 & q_2 \end{array} } \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%5B+%7B%5Cbegin%7Barray%7D%7Bcc%7D+p_1+%26+q_1+%5C%5C+p_2+%26+q_2+%5Cend%7Barray%7D+%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
then 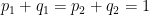
![{[a,b]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [a,b] S = [c,d]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ba%2Cb%5D+S+%3D+%5Bc%2Cd%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
so is ![{[c,d]}](https://s0.wp.com/latex.php?latex=%7B%5Bc%2Cd%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
At the end of a probabilistic computation we can ask what is the probability that the computation is in a given state. In our simple two-state example, we can get the value of
where 
Every step of a quantum computation must preserve that the total state is a unit vector. This implies that each step of the computation must be described by some unitary matrix 
then the rows are orthogonal unit vectors. If
![\displaystyle [a,b] U = [c,d]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ba%2Cb%5D+U+%3D+%5Bc%2Cd%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
so is
At the end of a quantum computation we cannot get the value of final unit vector. We can perform a measurement. This is perhaps one of the other strangest properties of quantum computations. For us a measurement is the following: If ![{[s_1,s_2,s_3,s_4]}](https://s0.wp.com/latex.php?latex=%7B%5Bs_1%2Cs_2%2Cs_3%2Cs_4%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

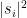
We cannot ask for the value of 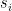


Deutsch’s Algorithm
At the highest level the algorithm
- Alice picks a special
dimension unit vector
.
- She asks Bob to apply a unitary matrix to
For each of these functions there is a different permutation matrix: Let’s use
to denote them. Note, permutation matrices are also unitary, and that Bob’s matrices are permutation because he is applying a deterministic computation. Of course Bob does not tell Alice which matrix he applies to the total state
.
- Alice applies a certain unitary transformation
. She then measures the resulting vector. If she gets
or
. Absolutely sure. If on the other hand, she gets
, or


Further, at least a positive fraction of the time, Alice will get the answer
This is the magic of quantum at work.
Why Does It Work?
The next key question is why can Alice figure out what Bob did? Or said another way, why does
Let’s look at what happened—it’s like unravelling a magic card trick. It really is simple once you think about

Alice’s vector is such that these four vectors are independent—in the usual sense of linear algebra. This relies on Alice selecting the start total state
Alice knows the set of vectors, she does not know which one occurs in any particular execution of the algorithm. It is not hard to show that there is a unitary transformation that moves these independent vectors in a nice way. Alice can pick a unitary transformation
![\displaystyle [\neg 0,*,*,*] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5B%5Cneg+0%2C%2A%2C%2A%2C%2A%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
the 
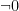
![\displaystyle [0,*,*,*] \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5B0%2C%2A%2C%2A%2C%2A%5D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
Alice then measures the vector 
That is the high-level explanation. I left out all the details, but I hope you follow the main thrust. The critical point is while Alice does not know what Bob does, she knows he has moved her starting total state to one of four total states. Her job is to find a measurement that can separate the cases in two groups. If you like all Alice needs is to find a separating hyperplane: essentially that is what a measurement is.
Thus, at some level the reason

I Cheated You
I left some details out, which I will now fill in. For example, I need to define Bob’s four permutation transformations. I also lied to you. Sorry. One complexity is that the four vectors
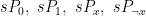
are not independent. But all is well as you will see. If you do not care to see all the details you can stop here. If you wish to really see what is happening, then read on.
Recall Alice works in a

For each boolean function 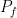

where 

The matrices ![{[a,b,c,d]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%2Cc%2Cd%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[b,a,d,c]}](https://s0.wp.com/latex.php?latex=%7B%5Bb%2Ca%2Cd%2Cc%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The key difficulty is when Bob applies his permutation matrices to Alice’s
Two Lemmas From Linear Algebra
If 
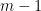
Lemma: Let
be a set of almost independent vectors in a finite dimension Hilbert space. Then for any nontrivial partition of
and
, there is a vector
and an
so that
for all
in the set
for all the
in the set


Proof: Let the vectors in the set 







Consider the vectors in 

for all 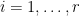
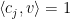
for all 
Thus, we can assume that they are only almost independent. The vectors

are independent. So 

Note, each coefficient 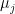
As before, there must be a vector
for all
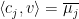
for all 
In order to complete the proof we need to show that

is not equal to zero. But this is equal to

which is non-zero. The lemma follows by taking 


We need a simple lemma that shows that four vectors that arise in the protocol are almost independent.
Lemma: Let
be a random unit vector. Consider the following four vectors:
Then with probability one the above vectors are almost independent.
![\displaystyle \begin{array}{rcl} &&[a,b,c,d] \\ &&[b,a,c,d] \\ &&[a,b,d,c] \\ &&[b,a,d,c] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%26%26%5Ba%2Cb%2Cc%2Cd%5D+%5C%5C+%09%26%26%5Bb%2Ca%2Cc%2Cd%5D+%5C%5C+%09%26%26%5Ba%2Cb%2Cd%2Cc%5D+%5C%5C+%09%26%26%5Bb%2Ca%2Cd%2Cc%5D+%5Cend%7Barray%7D+&bg=e8e8e8&fg=000000&s=0&c=20201002)
Proof: Consider the first three vectors. The key is the matrix 
![\displaystyle M = \left[ {\begin{array}{cccc} a & b & c & d \\ b & a & c & d \\ a & b & d & c \\ \end{array} } \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++M+%3D+%5Cleft%5B+%7B%5Cbegin%7Barray%7D%7Bcccc%7D+a+%26+b+%26+c+%26+d+%5C%5C+b+%26+a+%26+c+%26+d+%5C%5C+a+%26+b+%26+d+%26+c+%5C%5C+%5Cend%7Barray%7D+%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
must have rank
![\displaystyle \left[ {\begin{array}{ccc} a & b & c \\ b & a & c \\ a & b & d \\ \end{array} } \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%5B+%7B%5Cbegin%7Barray%7D%7Bccc%7D+a+%26+b+%26+c+%5C%5C+b+%26+a+%26+c+%5C%5C+a+%26+b+%26+d+%5C%5C+%5Cend%7Barray%7D+%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
It’s determinant is a homogeneous polynomial 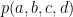
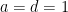
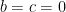
We must now, to complete the argument, show that with probability 
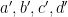
![\displaystyle [a'/r,b'/r,c'/r,d'/r]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ba%27%2Fr%2Cb%27%2Fr%2Cc%27%2Fr%2Cd%27%2Fr%5D&bg=ffffff&fg=000000&s=0&c=20201002)
is a unit vector. Here
Why is this useful? Well now we need compute the probability that
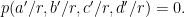
Since 
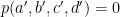
where
The other cases follow in the same manner.
Revisiting: Why Does It Work?
We can now see why the protocol works. By lemma 2, Alice can find a starting vector ![{s=[a,b,c,d]}](https://s0.wp.com/latex.php?latex=%7Bs%3D%5Ba%2Cb%2Cc%2Cd%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
are almost independent. Further, she can find the
Open Problems
Does this approach help you understand the power of quantum computing? Did I confuse you further? Or did this help?
Postscript
Ken Regan has pointed out that I should add several comments:
- How what I call
- How the power of quantum is usually explained.
- How a better algorithm can be constructed, one where Alice is always right.
Since this discussion is already very long, Ken and I will put together a longer piece in the near future that includes these points.


Question about the first lemma: Is there a similar result known for say a set of m-2 wise independent vectors?
Scott Aaronson’s explanation of quantum mechanics is the clearest I’ve read (from a computer scientist perspective): http://www.scottaaronson.com/democritus/lec9.html
I tried to simplify it as much as possible here: http://rweba.livejournal.com/429528.html
and here: http://rweba.livejournal.com/429744.html
Two comments on your explanation
(1) I hadn’t seen quantum algorithms explained in terms of looking for a separating hyperplane, that sounds very intriguing to someone from a machine learning background
(2) However the Wikipedia explanation also seemed pretty clear to me (unless I misunderstood)[http://en.wikipedia.org/wiki/Deutsch%E2%80%93Jozsa_algorithm]
(i)Create a superposition of |0> and |1>
(ii)apply a unitary transformation so that you end up computing f(0) XOR f(1). Voila, problem solved!
But I think your explanation does shed some more light on the situation.
Mugizi, indeed Dick and I were debating whether to give Deutsch’s original formulation, before deciding it could go into a later post. Here are three relevant paragraphs we decided not to include—I’m not taking time to make LaTeX show up in comments:
—————————————————-
In Deutsch’s original algorithm, $sP_0$ is a certain vector $v$ and $sP_1$ equals $-v$. Furthermore $sP_x$ is a vector $w$ that is orthogonal to $v$, and $sP_{\neg x}$ equals $-w$. The punchline is that by a single measurement, Alice can distinguish with certainty the subspace of $v,-v$ from that of $w,-w$.
In a particular representation, $v = (1,-1,1,-1)/2$ and $w = (1,-1,-1,1)/2$, and Alice’s $U$ is the $4 \times 4$ Hadamard transform $H^2 = H \otimes H =$ the tensor product of
$(1/\sqrt{2})[^1_1 \;{}^{\;\;1}_{-1}]$ with itself. The permutation matrices are the same as those used below, while Alice’s $s$ is $H^2$ applied to the basis vector $e_{01} = (0,1,0,0)$. Then Alice always gets answer $2$ when Bob chooses $P_0$ or $P_1$, and answer $4$ from $P_x$ or $P_{\neg x}$. We are trying, however, to think of linear-algebra structures apart from particular matrix and vector representations.
In the extended problem for $n > 1$ treated by Deutsch and Richard Jozsa, $f$ is a Boolean function on $\{0,1\}^n$ that is either constant or {\it balanced}, the latter meaning that $f(x) = 1$ for exactly half the arguments $x$. Now Alice and Bob work in
$2^{n+1}$-dimensional space, and Alice starts by transforming the basis vector representing $0^n 1$. There are exponentially many possible balanced $f$, so Bob has exponentially many matrices to choose from. Nevertheless, Alice can distinguish the cases with certainty after Bob uses just one of them, while in the classical case certainty requires exponentially many queries in the worst case.
————————————
I see you’ve named your own journal after my cryptic response to Bill Gasarch’s P vs. NP survey. Let me explain a little of what was behind it. In algebraic geometry (or specifically polynomial ideal theory) one can readily create candidate hardness predicates whose complexity surmounts the “Natural Proofs” obstacle, at least apparently. For example, given a polynomial p(x_1,…,x_n) over C or whatever field, define
M(p) = {monomials m: m belongs to the ideal formed by the first partial derivatives of p, but no proper divisor of m does}.
There are families of constant-degree p for which M(p) has cardinality 2^{2^n}, so a predicate of the form “|M(p)| > e(n)” where e(n) is super-exponential might not be decidable in exp(n) time. Unfortunately there are such p with linear-sized arithmetical circuits, so this candidate fails as a hardness predicate. Every other simply-stated predicate I’ve tried can be busted in a similar manner, even ones that try to involve Castelnuovo-Mumford regularity. A lot of these properties tie in to Betti numbers, which intuitively form a hierarchy of simplicity of concepts: connected components, then “holes”, then higher-dimensional stuff… The lower-order concepts have been exploited for moderate lower bounds on algebraic decision trees, for instance, but I came away convinced that any major breakthrough would have to grapple with the higher ones.
Whoops, the example p_n I mean give |M(p)| = 2^{2^r} where r = Theta(n).
Thanks Ken!
I actually understood a bit of that (I only have a vague idea of algebraic geometry but I’ve heard of Betti numbers).
I read Gasarch’s survey when I was starting grad school and for some reason I found the phrase “higher cohomology is inevitable” very amusing [I guess it’s the combination of the relative obscurity of “higher cohomology” with the unusual phrasing “is inevitable”]
Is your idea related to the Mulmuley-Sohoni approach or is that something very different?
Stupid question: Why is it that, “At the end of a probabilistic computation we can ask what is the probability that the computation is in a given state. In our simple two-state example, we can get the value of a, for instance.”? This sounds like the class PP, not BPP. At the end of a probabilistic computation, you should be able to sample from the distribution, or “measure” it, just like the quantum case.
We cannot ask for the value of s_i — this is not allowed. In a sense this is one of the real distinctions from probabilistic computation.
How is this a distinction? If you have a probabilistic algorithm ending in state 1 with probability a and state 2 with probability b, then at the end of a single computation you cannot “ask” for the value of a. The algorithm is either in state 1 or state 2. You can perform many computations and keep measuring the final state to approximate the value a, but this can also be done with a quantum algorithm, no?
Dave,
You are right. What I was trying to point out is unlike a usual computer, you can only get prob. information in both models.
Thanks
Once of the nicest things about quantum mechanics is that (as Feynman put it) “We are struck by the very large number of different physical viewpoints and widely different mathematical formulations that are all equivalent to one another. ”
In classical dynamics (for example) tangent vectors form a vector space, and so it seems natural to extend that linearity to the entire state-space … and it took more than 2,000 years for geometers to appreciate that this extension is not mathematically natural.
Similarly, in quantum dynamics the tangent vectors (to quantum trajectories) for a vector space, and in the 20th century it seemed natural to extend that linearity to the entire state-space … only now are we beginning to appreciate that this extension is not mathematically natural.
Dick, in your example the local-to-global extension of linearity is associated to the statement “apply a unitary matrix”. As Han Solo says in Star Wars: “Well, that’s the trick, isn’t it? And it’s going to cost you something extra!”
Here the point is that no-one has yet done any experiment quantum physics, in which a unitary matrix was applied that was associated to computational extravagance. And this is not for lack of trying, either! So maybe Mother Nature is trying to tell us something? And as usual … she is speaking the language of mathematical naturality.
Very nice explanation.
One suggestion: You use a, b, p1, etc. to represent real numbers in one paragraph, and then to represent complex numbers (I presume) in the next paragraph. Perhaps you could use different symbols or just make this distinction very clear in the text?
A technical nitpick: the first lemma holds only if C has at least 2 elements–which the proof implicitly assumes. For instance consider B = {(1,0,0), (0,1,0)} and C = {(1,1,0)}. I formed this example in my head while going over the statement of the lemma, and then had to figure out why it didn’t work out.
Not a nickpick—an error. But yes need at least two vectors. Thanks.
If I’m not mistaken, you are presenting the algorithm from Deutsch’s original paper, where with probability 1/2 Alice learns whether the function is constant or not with one query. But Alice can do this with probability 1, and I think the algorithm is simpler—and perhaps more instructive about quantum mechanics—than what you presented here.
Alice puts one bit x in the superposition (0+1)/sqrt(2), and the other bit y in the superposition (0-1)/sqrt(2). The student should contemplate what this means: at this point, the state is a tensor product, much like a product distribution in the classical case. The amplitudes psi (with a factor of 1/2 for normalization) are
x y psi
0 0 1
0 1 -1
1 0 1
1 1 -1
Bob then applies his function f to x and flips y if f(x) is true. If the function is constant, then the state is unchanged except for an overall sign. But if the function is not constant, then up to a sign it becomes
x y psi
0 0 1
0 1 -1
1 0 -1
1 1 1
This is a tensor product of (0-1)/sqrt(2) and (0-1)/sqrt(2). So if Alice now measures the first qubit in the basis { (0+1)/sqrt(2) , (o-1)/sqrt(2) }, she observes the first one if f is constant and the second one if f is not. Note that the state of the second qubit is (0-1)/sqrt(2) in either case — we are using the fact that this state is an eigenvector of the bit-flip operator, with eigenvalue 1.
This teaches the student about
. tensor products;
. the fact that overall signs, or phases, don’t matter;
. the fact that we can measure in different bases (and that we have to choose the right basis);
. the importance of using states which are eigenvectors of appropriate operators; and
. the “kickback” phenomenon, common to many quantum algorithms, of learning about a function by applying it to a superposition of inputs, and then measuring the _input_ state.
– Cris
The whole point of this discussion is to avoid tensor products, and all the rest.
But why would you want to? As you said in your presentation, quantum states are a lot like probability distributions. Then tensor products are just like product distributions.
As for “all the rest” — I really question whether there’s any point to presenting quantum computation in a way that doesn’t deal with the choice of basis, eigenvectors, unitary operators, and so on. The student ends up wading through more technical details without learning the important ideas. The amount of linear algebra the student needs is very small, and a lot of it comes up in classical CS theory as well (e.g. linearity testing).
More importantly, if you don’t teach the core ideas, how can the student get any “feel” for what other problems quantum algorithms might be able to solve?
For better of worse, quantum computing is now part of CS. We need to struggle to make it accessible, especially since CS students typically have a weak math background. But we should teach it and enjoy it.
In any case, thanks for making it a topic on your blog!
To put it more succinctly: if we don’t reveal the core ideas of quantum computing to the student, then Deutsch’s algorithm looks like an isolated “magic trick.” What we want to do is give at least a hint of how it leads to Bernstein-Vazirani, Simon, and finally to Shor’s algorithm.
Cristopher,
Thanks for taking the time to write the thoughtful comments.
I agree that in teaching we need to explain all you suggest. This was just a few pages, and I never meant it to replace a course. It was suppose to help give another viewpoint—thats all.
thanks again.
Well, as a physicist I’m already quite familiar with the “traditional” explanation (as the one by Cris)…
Anyway, the case of a 1-dimensional boolean function does not show any improvement over the classical case. Note that Alice has to measure 2 bits of information (1 out 4 possibilities). That is exactly the amount necessary in the classical case as well. A classical computation in parallel would be totally equivalent: one query needed. The power of quantum computation is only clear for higher dimensions, where Alice has to make N quantum measurements. An exponential improvement over the 2^(N-1) bits for the classical case in the worst scenario.
Holevo’s theorem shows that n+1 qubits cannot convey more than n+1 bits of classical information. Thus it is not 2^(N-1) bits that are the issue, rather saving that number of queries.
The real difference for n > 1 (IMHO) is that a lot of information goes into the promise that f is either constant or balanced. Knowing which alternative is true then seems to add little, in the case where you learn f is balanced.
For n=1 you are right: there is no “promise”, we have 2 qubits and hence 2 bits of information at our disposal, and Alice actually winds up with only 1 bit of info in either case.
Hmm, your explanation needs work.
(1)One can always represent the position of a CLASSICAL harmonic oscilator by a complex number z. Suppose you represent two harmonic oscillators by a pair of complex numbers (z,w). Let Alice’s state s equal (z,w). As far as I can see (maybe I’m wrong?), there is nothing in your game that distinguishes it when it’s played with two harmonic oscillators from it’s when played with two qubits. If this is true, then: either there is nothing particularly quantum in Deutsch’s algorithm (which I don’t believe), or your game does not represent the whole story about Deutsch’s algorithm
(2)You say:
“if Alice can only ask Bob for one evaluation of”
“Alice can determine whether Bob has selected a constant function or not in one evaluation”
Aren’t you are tacitly equating the cost of one evaluation by Bob to the cost of one measurement by Alice? (I think (2) is a clue to (1))
Dr. Tucci, thanks. Perhaps the material in my reply to Mugizi above, which we decided not to include in the post, clarifies the “whole story” regarding Deutsch’s algorithm—that it gives certainty and uses only 2 independent vectors?
Beyond that, I’m not sure what you mean. We acknowledge that Dick’s lemmas give a weaker conclusion than Deutsch obtains, but the next-to-last sentence in the Deutsch’s Algorithm section asserts it is still not obtainable classically. I don’t think we were confusing the #s of evaluations and measurements, so I don’t know what the “clue” is.
Sorry, I didn’t mean to sound mysterious.
My point (1) was that when Prof. Lipton says
“Alice picks a special 4 dimension unit vector.”
and
“The whole point of this discussion is to avoid tensor products”
he is already throwing away the quantum magic of Deutsch’s algoritm, IMHO.
For me an essential part of Deutsch’s algorithm is that n PHYSICAL particles, when they behave quantumly, live in a tensor product of n vector spaces. That you can encode any point of C^2 into two physical particles (qubits) with a total mass 2m. Or more generally, any C^n point into n qubits with a total mass n*m. Lipton stresses the linear algebra part, but you can always find a classical system that can be used to do the linear algebraic part of Lipton’s game. However, it would take a humonguous classical system of mass O(2^n)*m to do it, whereas a quantum system of mass n*m will do
I agree. Since everyone in computer science must already know tensor products—it is exactly what you do to expand out products of independent probability distributions—I don’t see the point of avoiding the issue, either.
Oops. I meant C^4 for 2 qubits and C^{2n} for n qubits.
Arrgh!! I meant C^4 for 2 qubits and C^{2^n} for n qubits. (it’s not rocket science: A tensor product space of n qubits has a basis of 2^n vectors, so if we give to each of those basis vectors one complex number amplitude, you get C^{2^n})
It is sad that Feynman’s quote, “I think I can safely say that nobody understands quantum mechanics,” has come to be used widely as an excuse for ignorance of a basic physical principle.
I would to express appreciation for both the original comments of Dick Lipton/Ken Regan and the alternative perspective supplied by Chris Moore.
Particularly attractive in the Lipton/Regan analysis is the natural links of its proof technology to contemporary topics in compressive sampling. But this also high-lighted a point of uncertainty (for me): it wasn’t evident (to me) how δ would scale with increasing numbers of qubits. As Chris Moore’s post points out, the Deutsch-Jozsa algorithm elegantly side-steps that problem.
Thus, one thing that I would very much like to see in the promised Lipton/Regan follow-on—which might naturally grow out of a discussion of the scaling of &delta—would be an easy-to-follow, physically motivated, and geometrically natural explanation of why the quantum separability problem is NP-hard … but this is asking a lot, I know.
It is interesting too, to reflect that if Dick’s blog entry were transmitted back-in-time thirty years (to 1980, say), all of its math and physics would have been completely understandable. What would have been hard-to-grasp back in the early 1980s would have been the overall narrative of quantum computing, and that narrative’s associated constellation of mathematically natural tools … this new narrative and its associated natural tools were Deutsch’s seminal contributions.
There’s no reason, therefore, why we can’t attempt to imagine how the physics and information theory behind the Deutsch-Jozsa algorithm might be described 30 years from now … `cuz heck … this description is very likely to change radically! And perhaps we need not invent new mathematics, or discover new physics, but rather, we can attempt to envision how the Deutsch-Jozsa narrative and toolset will continue to be repurposed and adapted in coming decades.
Such repurposing and adaptation reflects a very engineering point-of-view, that mathematical narratives are not a priori platonic entities, but (at least in part) are constructs that we ourselves design, to further our very human objectives … and these objectives include (of course) finding solutions for the very urgent problems that our planet is facing.
Moreover, there is an enjoyably transgressive aspect to repurposing narratives, both mathematical and otherwise. As Borges says in his short story Averroe’s Search: “In Alexandria there is a saying that only the man who has already committed a crime and repented of it is incapable of that crime; to be free of an erroneous impression, I myself might add, one must at some time have professed it.” And so, in order to envision the quantum narratives of the future, we must acknowledge, if not crimes, at least to having embraced erroneous impressions … which is fun!
To implement this look-ahead exercise, one possible starting point is Chris Moore’s own advice that “some of our favorite algorithms are best viewed as discrete versions of continuous algorithms”. Thus we can ask ourselves, “What does the Deutsch-Jozsa algorithm look like, if we describe it as a continuous flow, rather than as a sequence of algebraic transforms? And what narratives and proof technologies are naturally associated to this alternative point-of-view?”
John, we thank you for the nice reply, and especially for the pointer to Leonid Gurvits’ STOC 2003 paper, showing the NP-hardness of quantum separability (promise-)problems. Lots of other nice things in that paper and its predecessor linked there, plus these words from page 3 align with our motivations:
“We would like to stress that our paper does not contain explicit connections to Quantum Computing. It rather aims to study quantum entanglement from the point of view of classical computational complexity and computational geometry and to use some ideas and structures from Quantum Information Theory to construct and analyse classical algorithms.”
There is also recent work by Sevan Gharibian. We will take a look at these and try to answer your challenge. Ultimately we would like a linear-algebraic/geometric characterization of what quantum can do, though in some sense quantum already is that.
Regarding tensor product, I do regard it as algebraically fundamental of course—and I was interested in poly-size formulas over tensor and ordinary matrix product as a notion of “Quantum NC^1”, which Scott Aaronson essentially actuated in his “Skepticism/Multilinear Formulas” paper. We’d like to see it as no more than a way of tupling.
Thank you, Ken! I’ll read anything that you and Dick might post on separability with immense interest. Moreover, may I say that you and I have a shared interest in chess algorithms, and that I greatly enjoyed your guest-post on Dick’s blog earlier this year, titled “Can We Solve Chess One Day?”
I do have one major regret about my post … namely, that it misspelt Cris Moore as “Chris” Moore throughout. Doh!
Maybe I can make up for it with a link to Cris’ very good survey talk Continuous Methods in Computer Science.
PS: Ken, when I said “I’ll read anything that you and Dick might post on separability with immense interest.” … well … that was too weak of an appreciation.
Like a lot of folks, I read Leonid Gurvits’ article on the NP-hardness of quantum separability with great interest. But I don’t mind confessing that achieving an understanding of Gurvits’ result was completely beyond me … where by “understanding” I mean I came away with zero ability to sketch a simple, natural argument of why Gurvits’ theorem is true.
When it first appeared on the arxiv server, I read Sevag Gharibian’s (outstanding) article that you linked (which I see was subsequently updated four more times, and then accepted, so good on Gharibian!). And yet, I again came away with the frustrated feeling that I had not achieved any kind of physical or mathematically natural understanding of why quantum separability is NP-hard.
So if you and Dick have any approach in-mind to making these Gurvits/Gharibian separatibility theorems more accessible … well heck … that would IMHO be one of the most outstanding QIS blogposts ever. Even your willingness to think about it, and talk about it, is a pretty considerable service to the broader QIS community … for which this post is an appreciation.
John Sidles:
I again came away with the frustrated feeling that I had not achieved any kind of physical or mathematically natural understanding of why quantum separability is NP-hard.
Well…
Here as anywhere else this is the whole question:
What IS understanding?
What do you do/see when you understand as opposed to not understand?
What happens?
Is anyone out there able to articulate that?
Kevembuangga asks: Here as anywhere else this is the whole question: What IS understanding? What do you do/see when you understand as opposed to not understand? What happens?
One of the few benefits of growing older, is that experience teaches you that this question has many answers. Very broadly (for me, anyway) understanding is all about narrative and naturality … the “narrative” is the story you tell yourself about problems, and “naturality” is associated to the mathematical toolset you use to solve them.
In mathematics as in opera, there are many valid narratives, and many workable ideals of naturality. And this diversity is very good for mathematics (and for opera) … it is neither necessary nor desirable for everyone to think alike.
A wonderful short essay on this topic is Bill Thurston’s introductory essay to Daina Taimina’s Crocheting Adventures with Hyperbolic Planes. According to Thurston’s essay: “Mathematics sings when we feel it in our whole brain. People are generally inhibited about even trying to share their personal mental models. People like music, but they are afraid to sing. You only learn to sing by singing.” A book that develops this same general theme is Mac Lane’s Mathematics: Form and Function.
The general advice of these authors boils down to a straightforward recipe: you have create your own narrative about why you do mathematics (or science, engineering, medicine, etc.) and evolve a toolset that is natural for you … recognizing that the literature and your colleagues are eager to assist and inspire you … recognizing also that the main energy comes from within.
This process is evolutionary and unending, which is why it’s vital to enjoy the process itself. That’s I’m hoping that Dick and Ken will “assist and inspire” us, with a narrative about why the quantum separability problem is NP-hard … my own natural toolset (and seemingly, everyone’s?) being frustratingly inadequate to this challenge.
Simulation Mathematics 301 (Spring 2037)
Week 10: Elements of Spectral Naturality in Quantum Simulation
Prerequisites: During weeks 1–9 students have systematically acquired a practical grasp of:
algebraic naturality (extending through quaternions and tensor products),
geometric naturality (tangent and cotangent spaces, pushforward and pullback),
dynamic naturality (metric and symplectic structure, Hamiltonian potentials),
informatic naturality (Kählerian structure, Lindbladian potentials), and
thermodynamic naturality (Itô and Stratonovich processes, fluctuation-dissipation theorems, classical and quantum thermostats)
Synopsis: The focus of Week 10 is a rather specialized topic: spectral naturality in quantum dynamical systems. Topics covered include, eigenvalues and eigenvectors, unitary transformations, coarse-grained descriptions of measurement process as projective transformations, concluding with an overview of algorithms for quantum computation. This week is recommended for students who wish to develop a working familiarity with the 20th century literature on quantum physics, in particular students whose interests exend to the efficient simulation of strongly-coupled fermionic dynamical systems (quantum chemistry).
Option: Premedical students, and those quantum systems engineering majors whose interests are primarily in sensing-and-imaging, may elect instead to spend a week at the Hanford-Google Bioplex, which coordinates global access and open interface tools to the 1011 atomic coordinates that are presently flowing into the global biome database, daily, via the ongoing quantum spin biomicroscopy global survey.
Assignments: There will be three assignments, each due two (working) days after being assigned.
Lecture Sequence: The Monday–Wednesday–Friday lecture sequence will present the Deutsch–Jozsa algorithm, following the text of Lipton/Regan. Be sure you arrive at Monday’s lecture with a working grasp of the following key elements of spectral naturality: Hilbert spaces, qubits, Hamiltonian generators, spectral decompositions, and unitary transformations (for students who have never seen these topics, the TAs will provide backup tutorials).
• Monday’s Assignment (due Wednesday): Create a rank-2 tensor network state-space of 1024 spin 1/2 particles (the “qubits”). Define on that state-space the Lindbladian potentials necessary to initialize the qubits, the Hamiltonian potentials associated to the permutations operations of the 2-qubit Deutsch–Jozsa algorithm, and findlly the Lindbladian read-out potentials. Formally verify and validate the Lindbladian naturality of these dynamical flows, implement the 2-qubit algorithm, and provide numerical evidence that it “just works”. Answer the question: “In what sense is the rank-2 tensor network state-space isomorphic to a 2-spin Hilbert space?”
• Wednesday’s Assignment (due Friday): As above, but with a state-space rank of 128, and implement the 7-qubit Deutsch–Jozsa algorithm, both with and without concomittant noise processes associated to interactions with the “spectator” qubits. Justify your choice of noise model as being physically realistic. Answer the question: “In what sense is the rank-128 tensor network state-space isomorphic to a 7-spin Hilbert space?”
– Extra credit: write a 500-word essay, with *one* figure, on the topic: “The sensitivity of the Deutsch–Jozsa algorithm to noise processes”.
• Friday’s Assignment (due the following Tuesday): On the rank-128 state-space above, implement the Deutsch–Jozsa algorithm on 7, 8, 9, … 20 qubits, both with and without concomittant noise processes. Answer the question: “In what sense is the rank-128 tensor network state-space not isomorphic to a higher-dimension Hilbert space, and how does noise mimic/hide the geometric non-isomorphism?”
– Extra credit: write 1000-word essay, with *one* figure, on the topic: “Is the state-space of nature a Hilbert space?” Justify your conclusion with reference to the historical evolution of this question, the recent experimental literature, and the noise-induced dimensional compression that you observed in this week’s simulations.
I think one of the issues in explaining quantum algorithms to people is ironically that almost every description out there insists on tying it into computational complexity theory instead of simply presenting it as a new computational model. It artificially makes the descriptions tons more complicated than necessary by throwing in tons of material that has nothing to do with actual computation.
To me, it doesn’t matter whether something gets a provable scaling speedup as long as it has a decent likelihood of getting an actual speedup, since after all, we’re not using vacuum tubes anymore even though transistors give no scaling speedup. Then, one can quite easily describe quantum annealing, even to people who have little to no knowledge of quantum physics. It’s a very simple quantum algorithm and is very similar in concept to (classical) simulated annealing, so it’s easy to make comparisons and analogies for computer scientists.
Quantum annealing probably doesn’t provide an exponential speedup in the worst case, and may or may not give any scaling speedup, but that doesn’t matter, because we’re already spending exponential time to solve the problems that need to be solved.
A related comment: most of the material here is written with a specific computational model in mind (the gate model). While there are many advantages to trying to understand quantum computation using this model, the reality is that it is highly abstracted from what actually occurs in real quantum systems in the lab. I think part of the difficulty in explaining “the quantum magic” is that it is unclear even to physicists who specialize in experimental quantum information science how to make the gate model work in a real physical system, even at a conceptual level. If you can’t actually do the experiment for real, it’s no wonder you have trouble explaining how it works.
A big benefit of “realistic” models of quantum computation, such as quantum annealing, is that they are easily describable by real systems that actually exist in nature, such as quantum magnets. This makes describing how this type of quantum algorithm functions much more straightforward. The “quantum magic” effect is vastly reduced as you can actually perform all steps in solving real problems in the lab, and you can understand each of these in some depth.
Ultimately quantum computation is about harnessing what real physical systems actually do in nature, not about trying to make a physical system do something it doesn’t want to do. My view is that the gate model paradigm, and the dogma that it is “the one true path”, has significantly harmed advances in building real quantum processors because it’s not grounded in the reality of what can be done in practice. It arose from a computer science perspective and more or less ignores basic facts about the way the world works, such as thermodynamics.
I agree with most of what Neil and Geordie just posted … except for the criticism of what Geordie calls the “gate model.” Quantum gate models represent one class of quantum narratives and one mathematically natural toolset … and thus are intrinsically neither good nor bad … provided that we prudently keep in mind that other quantum narratives may prove similarly viable … and be mutually compatible too.
As the arch-trickster Feynman says in his Nobel Lecture: “There is always another way to say the same thing that doesn’t look at all like the way you said it before.” That is why it is well to read Feynman’s articles and lectures three times: the first time taking everything Feynman says at face value; the second time assuming he really means the opposite; then a third time attempting to reconcile the first two readings. And this triple-reading practice is particularly rewarding with respect to Feynman’s celebrated 1982 lecture Simulating physics with computers.
A pretty solid case can be made (IMHO) that among the most important resources that our planet has—in what is going to be a very challenging 21st century—is that quantum dynamics is sufficiently rich to encompass many narratives and multiple ideals of naturality … of which the discussion on this weblog has already touched upon several.
Since we are ourselves finite-temperature quantum-dynamical creatures, who are busy evolving within a finite-temperature quantum-dynamical universe, this diversity of mathematical narratives can be viewed as intrinsic to the human condition. We are still in the early stages of mathematically unravelling this dynamical diversity … which is very good news for everyone, and especially for young mathematicians, scientists, and engineers. 🙂
John: The gate model might be “mathematically natural” (I assume you mean that it’s similar to the way conventional computers are analyzed & designed so people are comfortable thinking in this way), but it’s not physically natural. Real physical systems are *all* open quantum systems with Hamiltonians with a ton of constraints. You can’t just imagine you can perform any operation consistent with quantum mechanics and expect to be able to built it in real life.
Geordie, I agree with your post 100% … and yet on the other hand … it’s undeniable that quantum gate analysis has hugely expanded our conception of how quantum mechanics really works.
Similarly, Maguzi’s praise of Scott Aaronson’s lecture series Quantum Computing since Democritus is IMHO completely justified. Scott’s lectures are terrific! And yet, it’s true too that students who learn only Hilbert-space/vector state quantum formalisms are severely handicapped.
It is historically significant (perhaps) that Dirac and von Neumann — the architects of the Hilbert-space/vector state — were themselves broadly conversant with multiple formalisms in classical dynamics. Nowadays, though, it is fairly common, even at the graduate levelm to encounter physics students who have never been exposed to modern ideas in classical dynamics; this lack imposes severe restrictions (IMHO) upon their appreciation of quantum dynamics.
Fortunately for future progress in quantum theory and mathematics, quantum experimentalists turn out to be — in my experience anyway — admirably non-doctrinaire. For example, last month I gave a lecture at the 3rd Nano-MRI conference that (in essence) retold the narrative of Nielsen and Chuang’s Quantum Computation and Quantum Information, using exclusively the symplectic tools of Arnold’s Mathematical Methods of Classical Mechanics. In particular, the lecture deliberately made no reference to Hilbert space and used no bra-ket vectors. As a deliberate provocation, the lecture concluded by asserting that the dynamical state-space of nature is perhaps not a Hilbert space, but rather is a low-dimension Kähler manifold (an idea that has been advocated by Abhay Ashtekar and Troy Schilling, among others).
Well, I had thought that abolishing Hilbert space from quantum mechanics would be controversial, but the (largely experimentalist) audience accepted it with the same phlegmatic insouciance with which Eastern Europeans accepted the fall of the Soviet Union … perhaps because the audience’s main practical concern was the predictive simulation of quantum spin biomicroscopy, for which purpose non-Hilbert quantum dynamical methods are well-suited.
It seems to me that this emerging diversity of quantum narratives is very good news for enterprises like D-Wave. For example, if it should happen that we discover (later in this century?) that nature’s undoubtedly quantum state-space is larger-than-classical, yet smaller-than-Hilbert, then we might find that the D-Wave-type superconductive devices are dynamically well-matched to the intrinsic geometry of these state-spaces. For this reason I am a pretty keen fan of D-Wave’s technology development effort … it would be great IMHO if the world had several more companies pursuing similar technology-oriented quantum research. `Cuz heck … how else are new jobs going to be created?
More broadly, the EU has a graduate program called Erasmus Mundus that requires its students to learn to speak more-than-one language … and it seems to me that students setting out to learn quantum dynamics are well-advised to learn more-than-one mathematical language too, for basically the same cross-cultural reason. After all, everyone is familiar with the fact that what seems mysterious, magical, or even impossible in one mathematical language, can seem natural, obvious, and even easy in another language.
And of course, there are *some* quantum phenomena, that seem to have no easy or natural description in *any* language … the NP-hardness of the quantum separability problem seems (to me) to be one of these unnatural quantum phenomena … such that we’re sure to learn a lot by thinking about it.
Geordie, I’m inclined to agree with you about quantum gates. Going further, is there any concrete work to the effect that the standard quantum circuit model may be too optimistic in its complexity assertions vis-a-vis the “real cost” of scaling up? Say by a factor of n, or maybe that for (well-entangled) n-qubit systems “t(n)” should really be “t(n^2)”? Either would result in the conclusion that Grover’s algorithm on n physical sites really takes linear(n) effort after all, whatever “effort” means…!?
The standard rebuttal is the quantum fault-tolerance theorem, involving just O(log n) overhead factors, but is Gil Kalai’s “How Quantum Computers Can Fail” paper still considered an effective critique of its probability assumptions?
Let me answer your question with a question 🙂
Why do you think there isn’t a *single* scalable fault tolerant quantum error correcting gate model architecture in the literature?
In Seattle we are big fans of gate-model research, and here’s why.
A specific example of gate-model work that has exerted a major incluence on our UW Quantum Systems Engineering group is descrived in Plenio and Virmani’s Upper bounds on fault tolerance thresholds of noisy Clifford-based quantum computers (arXiv:0810.4340, and references therein).
The mathematical elements of the Plenio/Virmani analysis are (in our view) admirably natural, ingenious, and elegant. For our engineering applications, we find it convenient to repurpose the Plenio/Virmani narrative from “noise is bad” to “noise is good.” Or more formally, “Obstructions to quantum computing (noise, measurement, thermalization) are essential to efficient quantum simulation.”
Nowadays, pretty much every scientist and mathematician appreciates Feynman’s principle that “We can describe (quantum mechanics) fully in several different ways without immediately knowing that we are describing the same thing.” And we engineers too have reason to embrace this principle, because by applying Feynman’s multiplicity principle systematically along lines that are essentially the same as the Plenio/Virmani analysis, we can create a powerful new mathematical toolset for practical quantum systems engineering.
That is the short story of why quantum systems engineers have nothing but *good* things to say about fundamental research in quantum information theory in general, and gate models in particular. There are sufficient opportunities here to keep mathematicians, scientists, and engineers … and companies like D-Wave … productively busy for an immensely long time. Good!
Well … since the blog is racing ahead … I’d like to post a couple of points …
Mainly, thank you Ken and Dick for a terrific topic! And I’ll definitely look forward to any further posts on the general theme of (as I think of it) geometric versus spectral understanding of quantum algorithms.
Second, I did write a longer essay on the general theme of ‘Some tough complexity questions that are associated to quantum naturality’ … but since that essay ended up being kinda long (and it included plenty of links) … so I just posted it to http://www.mrfm.org instead.
And now … like pretty much every other blogosphere life-form … I’m gonna read Vinay Deolalikar’s manuscript. Thanks again to everyone who helps make this planet’s research community so lively and great! 🙂