Barrington Gets Simple
On the power of bounded width computations

David Barrington is famous for solving a long standing open problem. What I love about his result is that the problem was open for years, his solution is beautiful, and also that he surprised us. Most of us who had worked on the problem guessed the other way: we thought for sure it was false. Again conventional wisdom was wrong. I wonder about other problems.
Bounded Width Computation
There are many restricted models of computations, without these weak models we would have no lower bounds. Proving in a general model–such as unrestricted boolean circuits–that an explicit problem cannot be computed efficiently seems to be completely hopeless. However, once some restriction is placed on the model there is at least hope that an explicit problem has a lower bound. Barrington worked on a restricted model called bounded width computations. While most (many? all?) of the community believed that this model was extremely weak and would yield lower bounds, he shocked us and showed that bounded width computations were quite powerful.
A bounded width computation is a way of computing a boolean function. Suppose that 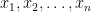
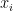
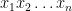
The key is that we restrict the number of bits that can be passed from one box to the next. In particular bounded width computations must have their boxes only receive and send 

The question that Barrington solved was: exactly what can bounded width computations compute with size at most polynomial? The conventional wisdom at the time was that such a model could not compute, for example, the majority function. My intuition–that was dead wrong–was that in order to compute the majority function the boxes would have to somehow pass the number of 

Barrington proved the following beautiful theorem:
Theorem 1 Any boolean formula of size
in can be computed by a
.
The theorem shows immediately that we were wrong. Since majority can be shown to have a polynomial size formula his theorem showed that the conventional wisdom was wrong. Often a weaker theorem is stated that shows that if the formula is depth 
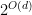

That formula’s can be made to have logarithm depth in their size without increasing their size too much has a long and interesting history. I do not have the space now to explain the details, but the key is that binary trees have good recursive properties–let’s leave it at that for now. Spira worked on the first result, then Brent, Pratt, and others. See Sam Buss’s paper for a recent result and some more background.
I will not give the full proof of Barrington’s Theorem, but will give an overview. His brilliant insight was to restrict the values that boxes pass from one to another to values from a finite group 
Barrington’s theorem is proved by showing that every formula can be computed by a bounded width computation over the same fixed group 
![{[x,y] = xyx^{-1}y^{-1}}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cy%5D+%3D+xyx%5E%7B-1%7Dy%5E%7B-1%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[G,G] = G}](https://s0.wp.com/latex.php?latex=%7B%5BG%2CG%5D+%3D+G%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The way that a bounded width computation will compute a formula is simple: if the formula is true let the output be the identity element 
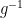
The key case is how do we do an “or” gate? Suppose that we want to compute 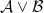


![{[a,b] = g}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D+%3D+g%7D&bg=ffffff&fg=000000&s=0&c=20201002)


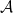
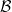
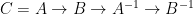
computes the “or”. The arrow 

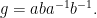
But this is the value that we needed. Pretty clever.
Related Results
I have some interesting related results that I wanted to talk about. Since this post is already getting a bit long I will explain some of the related work on Barrington’s Theorem in the future.
Open Problems
This area is rich with open problems. For starters we do not understand what groups are needed to make Barrington’s Theorem work. He shows that any non-abelian simple group is enough. In the opposite direction it is known that no nilpotent group will work. The big open question is what about solvable groups? We believe that they should not be able to compute the majority function, but we all guessed wrong before so perhaps we are wrong again. It is not hard to see that the exact technology that David uses will not work for solvable groups. But that, of course proves nothing. I consider this one of the most interesting open questions in this area of theory. The reason that nilpotent groups can be handled is that they are always direct products of p-groups. And p-groups can be handled by known results.
I have a completely wild idea that I hesitate to share less you stop reading my blog and think I have lost it. But I cannot resist so I will tell you it anyway. Suppose that you could prove from first principles that no group of odd order could compute the majority function. This would be a major result, since it would imply the famous (to group theorists at least) Odd Order Theorem of Walter Feit and John Thompson. They showed that any odd order group cannot be simple. So if no odd order group can compute majority, then by Barrington’s Theorem no odd order group is simple. The original proof of the Feit-Thompson Theorem is over 200 journal pages–255 to be exact.
A possible more doable idea would be to prove the also famous 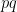
The reason I think that there is at least some hope that complexity theory could prove such theorems is that we bring a completely different set of tools to the table. I think it could be the case that these tools could one day prove a pure theorem of mathematics in an entirely new manner. That would be really cool.
Trackbacks
- Mathematical Embarrassments « Gödel’s Lost Letter and P=NP
- Guessing the Truth « Gödel’s Lost Letter and P=NP
- Can Group Theory Save Complexity Theory? « Gödel’s Lost Letter and P=NP
- Equations Over Groups: A Mess « Gödel’s Lost Letter and P=NP
- Lecture 11 « An Intensive Introduction to Complexity Theory (CMU, Spr 2011)
- Polls And Predictions And P=NP « Gödel’s Lost Letter and P=NP
- Surely You Are Joking? | Gödel's Lost Letter and P=NP
- Open Problems That Might Be Easy | Gödel's Lost Letter and P=NP


The link to the Sam Buss paper is broken. The correct link is http://euclid.ucsd.edu/~sbuss/ResearchWeb/fmlarestructure/paper.ps
Thanks I will fix it…dick ( My NAME, I perfer Dick to Richard)
Did you just call Andy Parrish a dick for pointing out the broken link?
NO…my name is dick. I hope you were kidding.
I better be careful. Did you see the Movie “Fracture”. In it Anthony Hopkins uses the “name Dick” it an amusing way.
Thanks for the kind words and for the nice clear explanation of my theorem. It is true that the result was surprising, and in fact I found the proof very shortly after I began to consider the possibility that the conjecture I was trying to prove (that the majority function required exponential size for any constant width) might be false. I had proved a special case of the lower bound for width 3 and failed to get the resulting paper into FOCS 1985, and in the resulting crisis of confidence I began looking at upper bounds to check my intuition. The construction with commutators entered into the lower bound proof, so I started looking at what upper bounds they could prove. I knew from my undergraduate algebra course that width 5 might behave very differently from width 3 with respect to commutators, since S_3 is solvable and S_5 is not. When I got the proof my advisor, Mike Sipser, was out of town, so I grabbed the first person I could find with the background to understand the proof, who turned out to be Phil Klein.
Someone on Lance’s blog just mentioned that a key step, perhaps the key step, in the discovery of the NL = co-NL theorem was the result by Lange, Jenner, and Kirsig that the alternation hierarchy for logspace collapses to the second level. This made it very easy to believe that the collapse to the first level (NL) was possible, and it was then a matter of months before Immerman and Szelepczenyi independently found the proof of that collapse. There was a similar short race to find the IP = PSPACE proof once that result became plausible.
Doesn’t the exact same proof you give in this post, word-for-word, apply to circuits instead of formulas? So I’m curious why you stated it only for formulas…
The key difference between circuits and formulas is that circuits can “re-use intermediate results”, while formulas cannot: the output of a circuit gate can be wired as input to any number of other circuit gates; however for using the same expression inside a formula you have to replicate it.
Note that the argument recursively creates computations for A and B in order to compute A v B., and then “wires them together”. If the computation of A and B would share some “common computation” we either have to replicate this common part for both A and B or “save” the intermediate result by adding more wires reaching from the “A” part of the computation to the “B” part. While the former voids the bound on complexity blowup, the latter voids the bound on the computation width.
Yes, I guess you are right…so how are circuits handled? (Barrington’s paper basically seemed to give the same argument given in this post.)
I think I’m missing something because it seems to me as if no such group can exist. By the properties of boolean negation:
Let x’ be the left inverse of x for all x
g’g = 1 by definition of left inverse
Let g’x be the negation of x for all x
g’g’x = x as a property of boolean negation
g’g’ = 1 after right-multiplying both sides by the right inverse of x
This means that:
g’g’ = 1 = g’g
Left-multiplying both sides by g’, you’re left with:
g’g’g’ = g’g’g
1g’ = 1g
g’ = g
With the commutator operation, we have:
g = [a,b] = aba’b’ for a,b not equal to 1
g’ = (aba’b’)’ = bab’a’ = [b,a]
[a,b] = [b,a], since g=aba’b’ is equal to its own inverse
This is only possible when a,b are commutative with one another. This means that A OR B = [a,b] = 1 = true for all A,B, which seems wrong. Moreover, it means that [a,b] = g = 1, which in conjunction with [a,b] = [b,a] implies that all elements used to construct any formula will always be commutative with one another, which contradicts the assumption that G is non-abelian.