Graduate Student Traps
Can we help avoid parallel repetition of mistakes?

Irit Dinur has recently again shown a wonderful skill at re-conceptualizing an area that had seemingly been well worked out. A notable previous instance was her re-casting the proof of the PCP Theorem as a progressive amplification. Now she and David Steurer have posted a new paper whose title, “Analytical Approach to Parallel Repetition,” introduces a new framework. The subject of parallel repetition, which they call “a basic product operation for one-round two-player games,” is distinctive in having its genesis in a mistake made in a paper—a trap of automatic thinking. Lance Fortnow and Mike Sipser thought that executing multiple instances of a randomized protocol in parallel would have the same power-law reduction in the probability of overall failure as executing them independently in sequence, overlooking how the strategies in the parallel cases could be dependent and exploit this.
Today we talk about similar traps that people can fall into even at advanced graduate level. How might they be avoided?
Truth-in-blogging note: this post is really about a different case of products and independence, and most of it was written months ago. It was lacking an intro section with someone to feature according to our “blog invariant,” and we also wanted a few short examples of graduate-student traps in computational theory and mathematics before progressing to the main one. The parallel repetition example came not only first to mind, but also second and third and fourth… as Dick and I struggled to think of more good ones. Lance’s haute faute has already been mentioned a few times on this blog, and I thought it would make a tiresome and repetitious parallel to my own “trap.” It didn’t help that the neat example I saw online years ago which furnished the phrase “graduate-student trap”—but which I didn’t preserve and forgot—has evidently vanished into unsearchability.
I was trying to decide between leading with the late-medieval mathematician-theologian Nicholas de Cusa for his advice on not pretending to have completed knowledge, or alternately a colleague in Buffalo who has compiled a good graduate-student advice list. Lance has similar advice, and when looking for it I spotted the mention of Dinur in his Twitter feed—actually Lance’s re-tweet of one by my former student D. Sivakumar. Voilà—Lance’s example it was. Thanks, Irit.
Traps
What is a trap? Pitfalls and paradoxes abound in mathematics and the sciences, and surmounting them is just part of acquiring the literature. Sometimes it is a confounding of preconceived expectations, but it is hard to find a way of defining such expectations that works for everybody or even most people. What makes a trap, in my opinion, is there being concrete indications in the concepts, in their contextual use, in their notation, or in the literature itself that run counter to the truth. Here are what strike Dick and me as a few simple but significant examples:



This contradicts the definition 






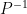


Well this is often not a bad error to make. Every matrix 

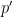
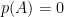


These are really at high school or undergraduate level, before the research stage. What kind of traps matter at research level?
My Trap
My own strongest feeling of falling into a “graduate student trap” came in October 2006, as I began my work on statistical claims of cheating with computers at chess that had arisen during the world championship match that month and before. I modeled a human player and a computer as distributions 

I decided to postulate that for two different (sets of) positions 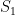
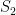
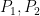





The first distance measure I considered, called Kullback-Leibler (K-L) divergence, is defined (on discrete domains 

Its Wikipedia page says straight out that 
Unfortunately, K-L is not symmetric, and more of concern to me, 

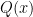
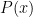
Is Jensen-Shannon Divergence Additive?
Applications employing distributional divergence measures were new to me, but it so happened that my department’s Distinguished Alumni Speaker that month knew something about them. After hearing my issues, he—I won’t name the “guilty party,” though I already did—suggested using Jensen-Shannon (J-S) divergence instead. J-S reduces this distortion by employing the interpolated distribution 

This always gives finite values, and is symmetric—hence the use of comma not 

A week later I started drafting a paper describing my concept and model, and decided it would be good to include a proof that J-S divergence is additive. Then, only then, is when I discovered with an electric shock:
It isn’t.
I’ll leave the task of actually constructing counterexamples to the reader, but here’s an intuition. It uses a generalizing trick that reminds me of one by Bob Vaughan that we covered last July. For any 

A little reflection may convince you that this cannot be additive for all 
How Clear in the Literature?
I can put this in the form of a “blog-beg” (sometimes called a bleg):
Can you find an easily-accessed source that says clearly that the basic Jensen-Shannon divergence is not additive?
As of this writing, the Wikipedia page on J-S still does have such a statement. Adding one yourself would be cheating. In 2006 I did not find one elsewhere, even in a couple of texts. My one-hour trial by Google when I first drafted this post last summer found one paper in 2008 titled “Nonextensive Generalizations of the Jensen-Shannon Divergence.” This clued me in that nonextensive is the antonym of additive. So the authors’ generalizations are not additive, but what about the original
Another paper I found had the promising title “Properties of Classical and Quantum Jensen-Shannon Divergence,” and even more, its first author and I have Harry Burhman as a common coauthor. It defines J-S with a bang in the opening sentence, states some generalizations of J-S, and (still on page 1) says the magic word:
Shannon entropy is additive in the sense that the entropy of independent random variables, defined as the entropy of their joint distribution, is the sum of their individual entropies. (emphasis in original)
But the next sentence brings up the different topic of Rényi entropy, and after a mention of “non-extensive (i.e. nonadditive) generalizations” of J-S it goes into quantum.
Another paper picks up the thread in its title, “Nonextensive Generalizations of the Jensen-Shannon Divergence.” The point of the first two words must be that the original J-S is additive, yes? It’s the generalizations that are non-additive. Right? The paper’s abstract says it builds something called the Jensen-Tsallis 
… the additivity property is abandoned, yielding the so-called nonextensive entropies.
The next paragraph introduces K-L and J-S, but doesn’t tell me whether the “abandoned” property was ever there. It seems that this simple knowledge is presumed, but how might a bright young graduate student—or an old one—find it in the first place?
Open Problems
Can you give some more examples of “graduate-student traps”? Ones that are helpful to know?
Is Jensen-Shannon divergence close to being additive, in some useful sense? This actually strikes me as a non-trappy, research-worthy question.


$Tr[AB]=Tr[BA]$
$Tr[ABC] = Tr[CAB] \neqTr[CBA]$
How is JS divergence useful in computational complexity?
Here is a closely related question on cstheory.SE, with more examples of potential “traps”: http://cstheory.stackexchange.com/questions/3616/common-false-beliefs-in-theoretical-computer-science
(In fact, Ken, you could add the examples from your post as answers.)
blogger trap: not putting http before arxiv URLs 😉
Thanks—I fixed the bad one. To answer about JS divergence in complexity, what I know generally offhand is that notions of distributional closeness are central to many hardness-versus-randomness type applications. Google finds me this paper which gets more specific about JS and complexity.
Very interesting. Thankyou.
I don’t get your point about square root! This a function. What you prove is that it is not compatible with multiplication (this is not an endomorphism of the monoid of complex numbers under multiplication). Still I agree that it can be a trap, but the title is misleading…
I think it’s a matter of interpretation. Maybe most accurate is to say there is no functional refinement of the square-root multi-function that is endomorphic on C, unlike the positive branch of sqrt over the nonnegative reals. As with logarithm, I think it’s having multiple branches that is fundamental to the failure of what we might expect from the reals.
sqrt *is* a function. The problem is not with sqrt. The problem is running with i * i = -1 as if it is an axiom consistent with the rest of the axioms of arithmetic, which apparently leads to the inconsistent result that i * i also equals 1.
Also, I’ve never heard of “X is not a function” before. Then, what is it? Are we defining a new logic with new types of elements? What are the exact rules concerning these new types of elements? What is known about this logic (completeness, etc.)?
From what I can find out, this is caused by the definition of sqrt. For reals sqrt(x) -> y such that y>=0 and y*y=x. However, letting i*i = -1 doesn’t quite allow us to claim that sqrt(-1) = i, because both -i and +i are candidates and neither of them can be compared to 0. +i is chosen by convention only from what I can see.
However, any of the choices invalidates the identity sqrt(a) * sqrt(b) = sqrt(a*b) because sqrt(-1) * sqrt(-1) is not equal to sqrt(-1 * -1) = 1.
The only way out that I can see is that declaring sqrt(-1) undefined.
The most common trap I run across has to do with Triadic Relation Irreducibility (TRI), as noted and treated by the polymathematician C.S. Peirce.
This trap lies in the mistaken belief that every 3-place (triadic or ternary) relation can be analyzed purely in terms of 2-place (dyadic or binary) relations — “purely” here meaning without resorting to any 3-place relations in the process.
A notable thinker who not only fell but led many others into this trap is none other than René Descartes, whose problematic maxim I noted in the following post.
• Château Descartes
Here is a budget of links to further exposition —
• Triadic Relation Irreducibility : 3
That’s very interesting! I had never considered this as a common fallacy, though I frequently encounter this issue.
Incidentally, my very first research project was exactly about measuring the difference between a triadic relation and its subsumed dyadic relations.
As mathematical traps go, this one is hydra-headed.
I don’t know how to put a prior restraint on the varieties of reducibility that might be considered, but usually we are talking about either one of two types of reducibility.
Compositional Reducibility. All triadic relations are irreducible under relational composition, since the composition of two dyadic relations is a dyadic relation, by the definition of relational composition.
Projective Reducibility. We take projections of a triadic relation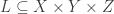 on the coordinate planes
on the coordinate planes 
 and ask whether these dyadic relations uniquely determine
and ask whether these dyadic relations uniquely determine  If so, we say
If so, we say  is projectively reducible, otherwise it is projectively irreducible.
is projectively reducible, otherwise it is projectively irreducible.
Ref. Relation Reduction
As a recent student, I (mildly) resent the condescension in the term “graduate student trap.” Especially when it’s used to describe mistakes made by professors.
Intendedly the opposite: higher than a high-school or college trap. I debated using the phrase “traps that could catch a Heffalump”, but that would have meant another paragraph explaining a well-worn reference. In grad school we teach the field to “youse guys” as peers. Anyway, that was the phrase I recall reading sometime prior to Oct. 2006, and which stuck in my mind at the time.
I’m total agree witch you guys.
The induction trap: Lets assume the statement for n and prove it for n+1 (after checking the base case). Now the statement for n looks already strong enough! Can’t we just be happy with the statement for n? If we assume the statement for n cant we just substitute n+1 for n? While proving things by induction you sometimes feel much closer to your target than you really are.
And sometimes, even going from 1 to 2 seems problematic.
And then there is the infinite inductive loop trap: you start proving some hypothesis by induction, you fall barely short to derive the n+1 case from n, so you go back, strengthen your hypothesis a bit and declare victory. But you should’ve checked if the inductive proof the stronger hypothesis goes through
I fell into the following trap:
A sequence of randomly generated integers is
almost always monotonically increasing.
Proof: Let the first number be n1.
Then there are n1 numbers below it and infinitely
many above it. Therefore randomly selected n2
will almost surely satisfy n2>n1, etc.
The trap here being that there’s no uniform probability distribution on the integers.
Indeed, one should define what it means for an arbitrary integer to be “randomly generated”. Whenever an algorithm chooses one randomly, it’s always among a finite set.
Hey, my favorite proof of Cayley-Hamilton’s theorem (because I can remember it). 😉
In one of his books on Omega, Chaitin explains thast he made a tremendous mistake defining omega for standard machines. But then realized that it does not make sense sinve the right definition should be for _prefix_ machines. I think that a similar mistake was also made by Solomonoff but I am not sure